

はじめに
最近、機械学習やデータ解析をしているひと達のツイッター界隈で「不偏分散はなぜ で割るのか」という問いが話題になっていた。私もこれまでそういうものだという認識でスルーしていたので、今回は厳密にその理由を示したい。
で割るのか」という問いが話題になっていた。私もこれまでそういうものだという認識でスルーしていたので、今回は厳密にその理由を示したい。
言葉の定義
対象とするサンプルの全体集合を母集団と呼ぶ。例えば対象がCCTの社員の身長であれば全社員の身長が母集団である。母集団の全サンプルから計算された平均値を母平均( )、母集団の全サンプルから計算された分散を母分散(
)、母集団の全サンプルから計算された分散を母分散( )と言う。1つのサンプルを
)と言う。1つのサンプルを で書くことにすれば次式が成り立つ。
で書くことにすれば次式が成り立つ。
![\begin{align*} \mu&=E[x] \\ \sigma^2&=E[(x-\mu)^2] \end{align*}](/wp-content/ql-cache/quicklatex.com-77484efbf915963fdd043aa891874932_l3.png "Rendered by QuickLaTeX.com")
ここで、![E[\cdot]](/wp-content/ql-cache/quicklatex.com-3941b329206b0baa01fad23b819cc5f7_l3.png "Rendered by QuickLaTeX.com") は母集団における平均操作であり、期待値と呼ばれる(後述)。
は母集団における平均操作であり、期待値と呼ばれる(後述)。
一般に、母集団に含まれる全サンプルを考えることはできないので、ランダムにサンプルを取り出すことになる。いま、 個のサンプルを取り出す場合を考え、各サンプルを
個のサンプルを取り出す場合を考え、各サンプルを と書くことにすると
と書くことにすると

を定義することができる。 が標本平均、
が標本平均、 が標本分散、
が標本分散、 が不偏分散(不偏標本分散)である。不偏分散が重要な理由は次式が成り立つためである。
が不偏分散(不偏標本分散)である。不偏分散が重要な理由は次式が成り立つためである。
(1) ![\begin{align*} \sigma^2=E[\sigma_u^2] \end{align*}](/wp-content/ql-cache/quicklatex.com-0e4927783c42d968daf647811b117524_l3.png "Rendered by QuickLaTeX.com")
つまり、不偏分散の期待値をとると母分散になるため、不偏分散は重要なのである。
証明
ここでは式(1)を示す。
![\begin{align*} E[\sigma_u^2]&= E\left[\dfrac{1}{N-1}\sum_{n=1}^{N}(x_n - \bar{x})^2\right] \\ &=\frac{1}{N-1} E\left[\sum_{n=1}^{N}(x_n - \mu+\mu-\bar{x})^2\right]\\ &=\frac{1}{N-1} E\left[\sum_{n=1}^{N}\Bigl\{ (x_n - \mu)^2 +2(x_n-\mu)(\mu-\bar{x}) +(\mu-\bar{x})^2\Bigr\}\right]\\ &=\frac{1}{N-1} E\left[ \sum_{n=1}^{N} (x_n - \mu)^2 +2(\mu-\bar{x})\sum_{n=1}^{N} (x_n-\mu) +\sum_{n=1}^{N} (\mu-\bar{x})^2 \right]\\ &=\frac{1}{N-1} E\left[ \sum_{n=1}^{N} (x_n - \mu)^2 -2N(\mu-\bar{x})^2 +N(\mu-\bar{x})^2 \right] \end{align*}](/wp-content/ql-cache/quicklatex.com-f7372bbb79ec74472af1bbd67eee8682_l3.png "Rendered by QuickLaTeX.com")
ここで期待値内の第2項に

を用いた。さらに計算を進めると
![\begin{align*} E[\sigma_u^2]&= \frac{1}{N-1} E\left[ \sum_{n=1}^{N} (x_n - \mu)^2 -N(\mu-\bar{x})^2 \right]\\ &= \frac{1}{N-1}\left\{ E\left[ \sum_{n=1}^{N} (x_n - \mu)^2 \right] -NE\left[(\mu-\bar{x})^2 \right] \right\}\\ &= \frac{1}{N-1}\left\{ \sum_{n=1}^{N} E\left[(x_n - \mu)^2\right] -NE\left[(\mu-\bar{x})^2 \right] \right\} \end{align*}](/wp-content/ql-cache/quicklatex.com-1c083ba71035f7ca59b08bc70ed3f6a8_l3.png "Rendered by QuickLaTeX.com")
となる。ここで母分散が
![\begin{align*} \sigma^2&=E[(x-\mu)^2] \end{align*}](/wp-content/ql-cache/quicklatex.com-6cf3eaf15fd976074c04d1c23f72d057_l3.png "Rendered by QuickLaTeX.com")
で定義されているので
![\begin{align*} E[\sigma_u^2]= \frac{1}{N-1}\left\{ N\sigma^2 -NE\left[(\mu-\bar{x})^2 \right] \right\} \end{align*}](/wp-content/ql-cache/quicklatex.com-06557bdf2a7257df10a3b64c460bfdd1_l3.png "Rendered by QuickLaTeX.com")
(2) ![\begin{align*} E\left[(\mu-\bar{x})^2 \right]&= E\left[\left(\frac{x_1-\mu + x_2-\mu+\cdots+x_n-\mu}{N}\right)^2 \right]\\ &=\frac{1}{N^2}E\left[\left(x_1-\mu + x_2-\mu+\cdots+x_n-\mu\right)^2 \right]\\ &=\frac{1}{N^2}\sum_{n=1}^NE\left[\left(x_n-\mu)^2 \right]\\ &=\frac{1}{N^2}\sum_{n=1}^N\sigma^2\\ &=\frac{1}{N}\sigma^2 \right] \end{align*}](/wp-content/ql-cache/quicklatex.com-0a6a92b4f3cea632ffbb0917d28885d7_l3.png "Rendered by QuickLaTeX.com")
が成り立つから
![\begin{align*} E[\sigma_u^2]&= \frac{1}{N-1}\left\{ N\sigma^2 -\sigma^2 \right\}\\ &=\sigma^2 \end{align*}](/wp-content/ql-cache/quicklatex.com-c15a7a15b6e6cf58961d2ec324b54a63_l3.png "Rendered by QuickLaTeX.com")
を得る。
補足
式(2)の右辺2行目から3行目への変換で、和の二乗を二乗の和に変換している。これが成り立つ理由は以下のとおりである。
![\begin{align*} E\left[\left(x_1-\mu+x_2-\mu \right)^2\right]&= E\left[\left(x_1-\mu)^2+2(x_1-\mu)(x_2-\mu) +(x_2-\mu)^2 \right]\\ &=E\left[\left(x_1-\mu)^2\right] +2E\left[x_1-\mu\right]E\left[x_2-\mu\right] +E\left[(x_2-\mu)^2\right] \end{align*}](/wp-content/ql-cache/quicklatex.com-cd4c53c368bba6ee062dc9f53f6e7669_l3.png "Rendered by QuickLaTeX.com")
ここで
![\begin{align*} E\left[x_1-\mu\right]&=0\\ E\left[x_2-\mu\right]&=0 \end{align*}](/wp-content/ql-cache/quicklatex.com-9f985fef7bd1daba50bc41c40a6faa38_l3.png "Rendered by QuickLaTeX.com")
が成り立つので
![\begin{align*} E\left[\left(x_1-\mu+x_2-\mu \right)^2\right]&=E\left[\left(x_1-\mu)^2\right] +E\left[(x_2-\mu)^2\right] \end{align*}](/wp-content/ql-cache/quicklatex.com-b9bd8fec3b1f7552e3a4b86addc38585_l3.png "Rendered by QuickLaTeX.com")
となる。2項以上の場合も同じである。交差項は常にゼロである。
最後に、期待値では何を計算しているのかについて触れておく。先に述べたように期待値は、母集団の全サンプルに対する平均値である。いまサンプルが確率 の割合で実現するとき量
の割合で実現するとき量 の平均値は
の平均値は
![\begin{align*} E\left[f(x)\right]=\int dx\;p(x)f(x) \end{align*}](/wp-content/ql-cache/quicklatex.com-0c1ea35598a40ad2f19be6dcfc88a7cc_l3.png "Rendered by QuickLaTeX.com")
で計算される。は確率であるから

が成り立っていることに注意する。今回の説明では、母集団からランダムに取り出したサンプルに番号をつけた( )。期待値を計算するときは、次のように個々のサンプル変数が積分変数になる。
)。期待値を計算するときは、次のように個々のサンプル変数が積分変数になる。
![\begin{align*} E\left[f(x_n)\right]&=\int dx_n\;f(x_n)p(x_n)=\int dx\;f(x)p(x) \end{align*}](/wp-content/ql-cache/quicklatex.com-c05a24b7c3666db3f2a00760612e45f0_l3.png "Rendered by QuickLaTeX.com")
すなわち
![\begin{align*} E\left[f(x_1)\right]=E\left[f(x_2)\right]=\cdots=E\left[f(x_N)\right] \end{align*}](/wp-content/ql-cache/quicklatex.com-71d8cbec7ed4cdd330807dc3cbdff6d5_l3.png "Rendered by QuickLaTeX.com")
が成り立つ。
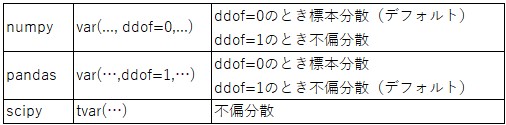
Pythonライブラリの分散
各種Pythonライブラリが提供する分散が、標本分散なのか不偏分散なのかは注意が必要である(下の表を参照)。
まとめ
今回は不偏分散について取り上げ、その期待値が母分散と一致することを示した。また、Pythonの各種ライブラリが提供する分散が、標本分散なのか不偏分散なのか関数名だけからは分からないことにも触れた。
ところで、不偏分散の英語表記はunbiased varianceである。標本分散の期待値は母分散にならない(バイアスがかかっている)が、不偏分散の期待値は母分散になる(バイアスがかかっていない)、という意味のようだ(多分)。