

こんにちは、エンジニアのtetsuです。
どうしてモデルがこのような予測をしたのか、ということを説明することの重要性は近年ますます高まっているように思えます。これには予測結果の解釈をおこなうことで様々な知見を得たいという要求や、ブラックボックスのモデルは信用しづらいというのが理由に挙げられます。
線形回帰や決定木といったモデルは予測結果に対する解釈をすることができますが、単純で表現力が乏しいです。一方でディープラーニングや決定木のアンサンブル学習などの複雑なモデルは表現力が高いですが、人間が解釈しようとするのは困難です。
このような問題を解決するために近年は様々な手法が提案されています。今回はそれらの中の1つであるSHAP(SHapley Additive exPlanations)について簡単にご紹介します。SHAPは日本語だと「シャプ」のような発音のようです。
なお、SHAPについては以下の文献を参考にしています。
- A Unified Approach to Interpreting Model Predictions
- Consistent Individualized Feature Attribution for Tree Ensembles
SHAPの概要
SHAPはモデルの予測結果に対する各変数(特徴量)の寄与を求めるための手法です。例えば、分類問題用のモデルが正解ラベルを予測できたとして、入力データの各変数がプラスに働いたのか、あるいはマイナスに働いたのかなどを知ることができます。
SHAPでは入力![{\mbox{\boldmath $x$}}=[x_1,\cdots,x_M]^T](/wp-content/ql-cache/quicklatex.com-6a670e3cba80681608a01bd9e2da5e84_l3.png "Rendered by QuickLaTeX.com") と学習したモデル
と学習したモデル が与えられたとき、モデルを各変数の寄与が説明しやすい簡単なモデルで近似します。具体的には次のようなモデル
が与えられたとき、モデルを各変数の寄与が説明しやすい簡単なモデルで近似します。具体的には次のようなモデル で近似します。
で近似します。
![\begin{eqnarray*} g({\mbox{\boldmath $z$}}') = \phi_0 + \sum_{i=1}^M \phi_i z_i',\ {\mbox{\boldmath $z$}}'=[z_1',\cdots,z_M']^T.\end{eqnarray*}](/wp-content/ql-cache/quicklatex.com-fcc2d1118d3711ad850ed8252761c149_l3.png "Rendered by QuickLaTeX.com")
ここで各 は例えば
は例えば の
の 番目の変数が観測されていれば1、そうでなければ0となります。今求めたい変数の寄与は上式での
番目の変数が観測されていれば1、そうでなければ0となります。今求めたい変数の寄与は上式での になります。モデルで使われている各は入力データの値が変われば、その都度求める必要があることに注意してください。
になります。モデルで使われている各は入力データの値が変われば、その都度求める必要があることに注意してください。
SHAPではモデルに対して次の性質を持つように制約を加えます。
- local accuracy:
 の和は説明したいモデルの出力値
の和は説明したいモデルの出力値 と等しい
と等しい - missingness:
 のときは
のときは
- consistency:ある変数のモデル
 の出力に対する影響力が大きければ、その変数の寄与は大きくなる(が大きくなる)
の出力に対する影響力が大きければ、その変数の寄与は大きくなる(が大きくなる)
 と等しい
と等しい のときは
のときは
実は上記の性質を持つようなは一意に定まることが示されています。この一意に定まるはゲーム理論ではShapley値と呼ばれるものと同じです。このため、変数の寄与を求める問題はShapley値を計算する問題に帰結します(実際はSHAPではこのShapley値とは少し異なるSHAP値というものを求めますが、詳しい話は置いておきます)。Shapley値はゲームにおいてプレイヤーが連携したときの各プレイヤーの寄与をあらわすものということなので、変数の寄与を求めることがShapley値を求める問題に帰結するのも納得がいく部分があるかと思います。
SHAP値の計算を愚直におこなうと、計算量が多くなりますが、ある程度の仮定をおくことで少ない計算量で近似値を計算することができます。ただし、勾配ブースティング法などの決定木を用いたアンサンブル学習では高速に真値を求めることができます。
実験
ここでは勾配ブースティング法のモデルと画像分類用のディープラーニングのモデルであるVGG16の予測結果をSHAPによって解釈する実験をおこないます。
SHAPはこちらのライブラリを使用させていただいています。
TreeExplainer
まず分類問題用のデータを用いて勾配ブースティング法のモデルに学習させ、このモデルを用いたときの予測結果に対する各変数の寄与をみてみます。データはkaggleの導入で使われるタイタニック号の各乗客が生存できたかどうかを予測する問題のものを用います。勾配ブースティング法のライブラリはLightGBMを用いました。
データがもつ変数としては各乗客が購入したチケットのクラス(Pclass 1、2、3の順で高いクラス)、料金(Fare)、年齢(Age)、性別(Sex 男=1、女性=0)、出港地(Embarked 便宜上Southampton=1、Queenstown=0、Cherbourg=-1とおく)、部屋番号(Cabin)、チケット番号(Ticket)、乗船していた兄弟または配偶者の数(SibSp)、乗船していた親または子供の数(Parch)となります。今回は部屋番号とチケット番号の変数は削除し、また特に変数は追加しないでおきます。これらの変数を用いて、生存できたかどうかの予測をおこなうモデルを学習させます。
1つの入力データに対する予測結果の解釈を得るためには、学習させたLightGBMのモデル(ソースコード上でのbst)を用いて次のように実行します。
|
1 2 3 4 5 6 7 8 |
import shap shap.initjs() explainer = shap.TreeExplainer(bst) shap_values = explainer.shap_values(X_train) # X_trainは訓練データのpandas.DataFrame shap.force_plot(explainer.expected_value, shap_values[0,:], X_train.iloc[0,:]) |
この結果は次のようになります。

この図は、LightGBMのモデルの出力の生の値1.58(これにシグモイド関数を適用すれば、生存者である確率になります)を計算する際の各変数の寄与をあらわしています。LightGBMの出力値を大きくするのに寄与した変数を赤で示しており、値を小さくするのに寄与した変数を青で示しています。寄与の大きさは変数名の上にある色付きの枠の大きさになります(例えば、Age=9という値はLightGBMの出力値に対して2.7程度の寄与があるという見方になります)。出力結果をみると、Sex=1(男性)とPclass=3(チケットのクラスが低い)が生存者である確率を下げていますが、一方で9歳という低い年齢が生存者である確率を大きく押し上げています。子供が優先されて救命ボートに乗せられたことが反映されているようです。
また複数のデータに対する変数の寄与を色々な形で表示することも可能です。その1つの例として次を実行してみます。
|
1 |
shap.summary_plot(shap_values, X_train) |
これにより次が表示されます。
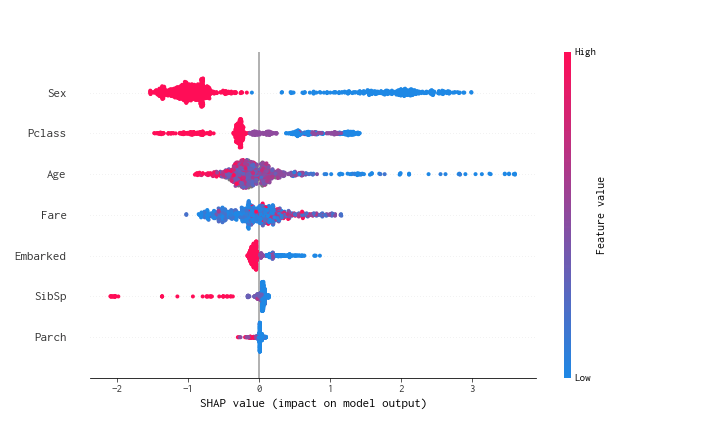
これは各変数毎に訓練データのSHAP値(寄与)の分布をバイオリン図のようにあらわしています。右側にいくほど寄与が正の向きに大きく、左側にいくほど寄与が負の向きに大きくなります。点によって色が異なりますが、赤色に近いと変数の値が大きく、逆に青色に近いと値が小さいです。例えばSexをみると青色の点(Sex=0なので女性)がSHAP値が正のほうに多く存在し、逆に赤色の点(Sex=1なので男性)がSHAP値が負のほうに存在します。これは女性のほうがより生存しやすいと予測するモデルになっていることをあらわします。ほかにもPclass(チケットのクラス)やAge(年齢)も生存確率への寄与が大きいモデルになっていることがわかります。
変数の寄与の絶対値の平均値も簡単に表示でき、スクリプトとグラフは次のようになります。
|
1 |
shap.summary_plot(shap_values, X_train, plot_type="bar") |
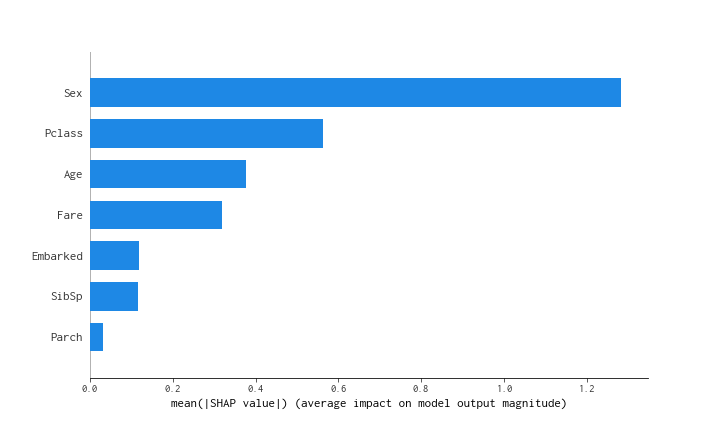
値が大きいほど、モデルが重要視している変数であると解釈できますので、性別が予測に非常に重要であるということがわかります。
またSHAPとは別にLightGBMやXGBoostでは学習をおこなうことで、ある種の変数の寄与を計算することが可能です。こちらもスクリプトと図を以下に示します。
|
1 |
lightgbm.plot_importance(bst, max_num_features=10) |
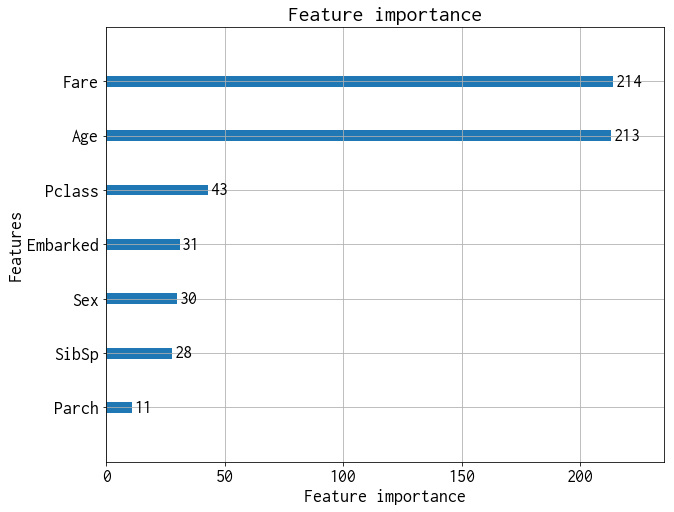
この変数の寄与の算出結果では性別の寄与が低く見積もられていることがわかります。感覚的には性別が重要そう(女性が救命ボートに乗るのが優先された)ですので、SHAPによる変数の寄与と比べて、こちらの変数の寄与の計算結果は人間の感覚とは一致していないように感じられます。この種の変数の寄与の計算はconsistencyが満たされていないため、これが要因となっているのかもしれません。consistencyが満たされないことは文献で指摘されていますので、気になる方はこちらを参照ください。
DeepExplainer
次にディープラーニングの画像分類のモデルのVGG16(事前学習済み)を使った実験をおこないます。このVGG16に画像を適当に与えて、その予測結果に寄与が大きかった画像の部位を確認してみます。スクリプトは次のとおりです。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 |
from keras.applications.vgg16 import VGG16 from keras.applications.vgg16 import preprocess_input from keras.preprocessing.image import load_img, img_to_array import keras.backend as K import numpy as np import json import shap import matplotlib.pyplot as plt layer = 7 model = VGG16(weights='imagenet', include_top=True) X,y = shap.datasets.imagenet50() def map2layer(x, layer): feed_dict = dict(zip([model.layers[0].input], [preprocess_input(x.copy())])) return K.get_session().run(model.layers[layer].input, feed_dict) e = shap.DeepExplainer( (model.layers[layer].input, model.layers[-1].output), map2layer(X, layer), ) # "image.png"に対象のファイルパスを指定 img = load_img("image.png", target_size=(224, 224)) array = img_to_array(img).reshape(1, 224, 224, 3) url = "https://s3.amazonaws.com/deep-learning-models/image-models/imagenet_class_index.json" fname = shap.datasets.cache(url) with open(fname) as f: class_names = json.load(f) shap_values,indexes = e.shap_values(map2layer(array, layer), ranked_outputs=1) index_names = np.vectorize(lambda x: class_names[str(x)][1])(indexes) shap.image_plot(shap_values, array, index_names, show=False) plt.gcf().set_size_inches(20, 20) |
このスクリプトを実行した結果が以下になります。
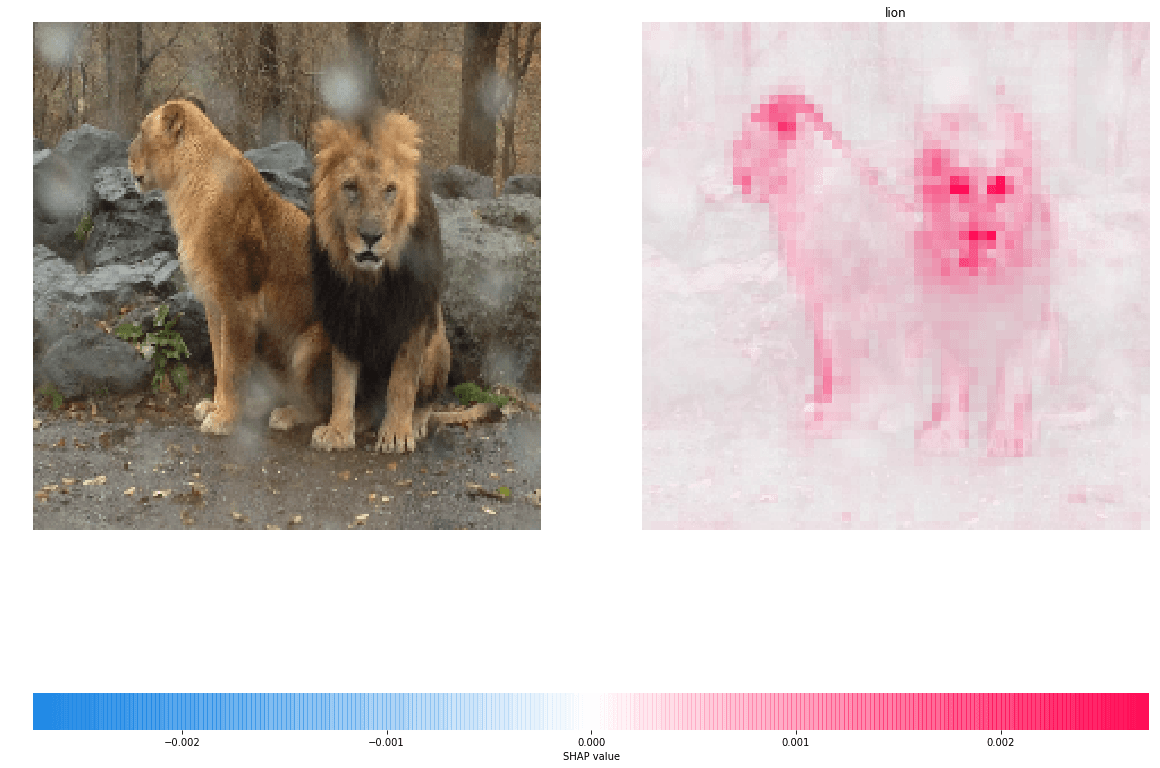

左側のライオンとお城(どこのお城か分かりますか?)の画像がそれぞれ入力になります。VGG16の識別結果はそれぞれ正しいものとなっています(右側の画像の上の文字列が予測結果)。右側の画像の赤色が濃い部分が予測結果への寄与が大きい部分になります。ライオンの画像では目と鼻付近が濃い赤になっていますので、この部分がライオンと判定するのに大きく寄与しています。またお城の画像では瓦の部分の寄与が大きいことがわかります。このことからVGG16は識別に必要な部分に正しく着目できていると言えそうです。
終わりに
今回は勾配ブースティング法とディープラーニングのモデルに対してSHAPを適用して実験をおこないましたが、任意のモデル向けのモジュールもあります。非常に有用な手法だと思いますので、ぜひ活用していきたいですね。