

こんにちは、エンジニアのBBです。
皆さんは線形回帰と聞いてどのようなものか明確に説明できるでしょうか。
なんとなくのイメージは出来るけど……と、明後日のほうを見ながら言う方を対象にちょっと前までそんな感じだった僕が説明していきます。
線形回帰とはなにか
まずはこの図を見てください。
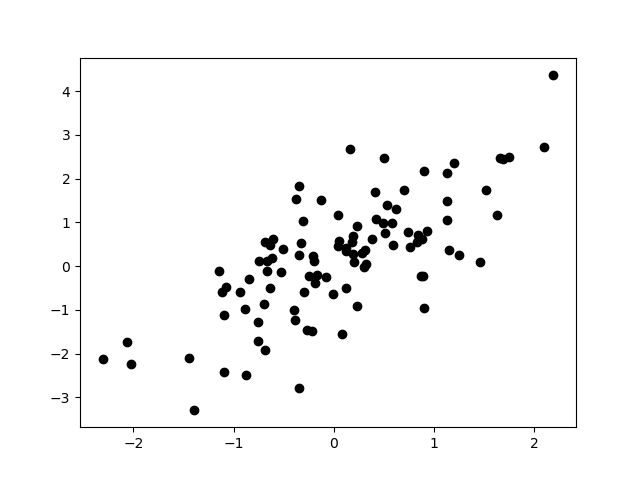
あなたは左下から右上にかけてまっすぐに線を引きたくなったのではないでしょうか。こんな具合に。
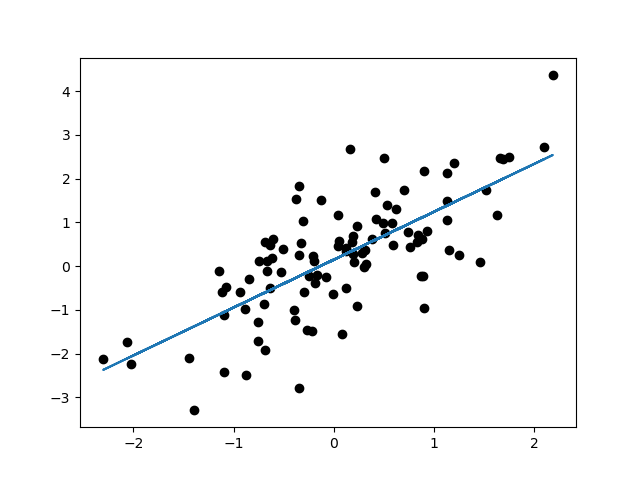
このいい感じに線を引く操作を一定のルールに従って行うことを線形回帰といいます。いい感じに引かれた線は、未知の値(横軸)に対しておおよその答え(縦軸)がどのあたりに位置するかを予想してくれたり、変な値を見つけることに役立ちます。今回は線形回帰について数式を解きつつ、pythonのオープンソース機械学習ライブラリscikit-learn(通称:sklearn)に入っている線形回帰用のツール、LinearRegressionの偉大さを感じていきたいと思います。
機械学習はこの手順が基本!
さて、いきなり話がそれますが機械学習における基本的な手順を説明させてください。手順を把握しておくことで、テクニカルワードや数式の位置づけを体系的に理解する道しるべになると思います。機械学習の手順は大雑把に分けて3つです。
- データを用意する
- モデルを訓練する
- モデルを評価する
この3つを繰り返してモデルの精度を改善していきます。上記手順のそれぞれにそれっぽい名前の手法や言い回しがあり、慣れないうちはすぐ迷子になるので意識的に自分がどの位置にいるのかを確認しておくといいと思います。
1.データを用意する
機械学習にはもちろん解析対象になるデータが必要になります。冒頭の図に使ったx, yのデータもそうですし、画像や文章も解析対象データとなります。解析対象のデータは必ず数値や数値の並び(行列やベクトルなど)に落とし込む必要があります。現実世界の現象をいかに数値に落とし込むかが機械学習の成功のカギとなり、データ活用の全行程の約8割をつぎ込む重要手順となっています。
2.モデルを訓練する
機械学習の名前の通り「機械」に手順1で用意したデータを「学習させる(訓練する)」工程です。モデルと一口に言っても様々あり、解析対象によっては自作する必要があるかもしれません。今回のテーマである線形回帰もこのモデルの一つとなります。
3.モデルを評価する
モデルで計算した結果(これもモデルによって形式はイロイロ)を評価する工程です。評価が悪かった場合は、手順1に戻ってデータを加工したり、手順2でモデルのチューニングやモデル自体を変更したりと頑張ります。
線形回帰でボストンの住宅価格データをみてみよう
ここからは数式の説明を交えつつ、線形回帰をpythonを使って実装していきます。また、線形回帰用ツール、LinearRegressionとの計算結果と比較して「やっぱ出来合いのツールスゲーわ」という感じで締めくくります。先述に合わせ、手順3つでこれからすることをざっくり説明します。
1.データを用意する
sklearnが用意してくれているサンプルデータ、ボストンの住宅価格データを使います。
データは、住宅価格とその他その住宅に関するステータス13項目がひとまとめになっており、それが約500軒分あります。イメージとしては横軸にステータス13項目(一気に図示できませんが。。)、縦軸に住宅価格をとって線形回帰をする感じです。住宅のステータス13項目を使って住宅価格を求めるとすると、ステータス13項目を説明変数、住宅価格を目的変数といいます。
2.モデルを訓練する
モデルは宣言した通り、線形回帰を実装します。比較対象のツールはsklearnのLinearRegressionを使います。
3.モデルを評価する
結果の評価についてはRMSEをいう指標を使いますが、細かいことは後で記載します。
1.データを用意する
今回は出来合いのデータを用いるのでこのステップは飛ばしてステップ2から始めましょう。
2.モデルを訓練する
ここでは主に式を交えつつの説明をしていきますが、ここでの最終目標をまず見ておきましょう。
(1) 
これです。このパラメータ を求めることがゴールです。
を求めることがゴールです。 は物件のステータス、
は物件のステータス、 は予想された物件価格を表し、「ステータスから物件価格を予想する」式となります。このような関係をはパラメータに対して線形であるといいます。式(1)は行列、ベクトルが使われているので正直、慣れていないと何を言っているのかわからないと思いますので次の3ステップで考えていきましょう。
は予想された物件価格を表し、「ステータスから物件価格を予想する」式となります。このような関係をはパラメータに対して線形であるといいます。式(1)は行列、ベクトルが使われているので正直、慣れていないと何を言っているのかわからないと思いますので次の3ステップで考えていきましょう。
- ステータス1項目、1軒分のデータを使う
- ステータス1項目、全軒分のデータを使う
- ステータス13項目、全軒分のデータを使う

徐々に、データ構造を複雑にしていっているのがわかると思います。
1.ステータス1項目、1軒分のデータを使う
ステップ1では式(1)はこんな感じになります。
(2) 
式(2)が意味するところは (予想の住宅価格)は
(予想の住宅価格)は (ステータス1)に
(ステータス1)に を掛けたものと定数
を掛けたものと定数 を足したものということです。これを図に起こすとこうなります。
を足したものということです。これを図に起こすとこうなります。
そもそも点が1つしかなくこの点さえ通っていればなんでもよいので、いい感じの線は決められそうにありません。なので式(2)の出番はなさそうです。
2.ステータス1項目、全軒分のデータを使う
ステップ2では式(1)はこんな感じになります。
(3) 
式に使われている文字の頭に矢印がっくついてがなにやら不穏な感じになっていますがこれはベクトルといいます。身構える必要はなく、単純に全軒分のデータに対してステップ1の式を書くのが面倒なのでこのように表記した単なる省略記法とかそんな感じにとらえてもらえるとわかりやすいと思います。実際はこんな感じの式が隠れているのです。

文字をベクトルとして表記するとこんな感じになります。

今回使うデータは506軒分ありますので となります。506個のに対して、予想住宅価格も506個ありますのでベクトルとなります。ここまで省略すると欲が出てきます。式(3)にはとという似たような表記が出てきています。まあ、こちらのさじ加減なのですが、この2つも下のようなベクトルを使って省略することができます。
となります。506個のに対して、予想住宅価格も506個ありますのでベクトルとなります。ここまで省略すると欲が出てきます。式(3)にはとという似たような表記が出てきています。まあ、こちらのさじ加減なのですが、この2つも下のようなベクトルを使って省略することができます。

省略するためにここで にちょっと下に示すような細工をしておきます。
にちょっと下に示すような細工をしておきます。

このようなベクトルのレベルアップ版を行列といいます。読んで字の通り行と列を持っています。このとを使って式を変形するのですが、行列とベクトルの掛け算はちょっと複雑です。こちらの図がわかりやすかったので拝借します。

この図にあるような順で掛け算が行われるため、追加した1を並べた列がを作ってくれます。
式(3)はこんな感じに変形されます。
(4) 
式の変形が完了しましたので今度はを求める作業に入っていきましょう。を決定するには式(4)で引かれる線が最も「いい感じの線」になることが条件ですが、「いい感じの線」とはそもそも何でしょうか。「いい感じ」を考えるにあたり最小二乗法という手法を引っ張ってきます。最小二乗法を今回に当てはめると、をいろいろ変えて全ての「計測された住宅価格 」と「予測された住宅価格」の差を2乗した値の和が最も小さくなった時に「最もいい感じの線」が決まります。上記を式にするとこうなります。
」と「予測された住宅価格」の差を2乗した値の和が最も小さくなった時に「最もいい感じの線」が決まります。上記を式にするとこうなります。
(5) 
式(5)に出てきた は先述と同じくデータの数を示しています。506軒分のデータがありますので今回は
は先述と同じくデータの数を示しています。506軒分のデータがありますので今回は となります。
となります。 は右にくっついてる式を
は右にくっついてる式を 1~まで足し続けなさいという意味です。シグマと読みます。式の右側はある数値の2乗なので常に正の値になります。ある数値は実数値の前提です。ちなみに機械学習の教科書等ではある数値
1~まで足し続けなさいという意味です。シグマと読みます。式の右側はある数値の2乗なので常に正の値になります。ある数値は実数値の前提です。ちなみに機械学習の教科書等ではある数値 が実数であることを示すとき
が実数であることを示すとき のように表記されることがあります。不意をついて現れるため慣れない人にとっては恐怖の対象だったかもしれませんが、こういった意味で使われているだけなのでもう怖がる必要はありません。
のように表記されることがあります。不意をついて現れるため慣れない人にとっては恐怖の対象だったかもしれませんが、こういった意味で使われているだけなのでもう怖がる必要はありません。
ここで興味があるのは式(5)ではなく、式(5)の左側が最も小さくなるのみです。そんなもんわかるかいと思われるかもしれませんが、右側はの2次関数になっているので求めることができます。2次関数はあるで最小値となるのですが、2次関数の形がわからない方はこちらのサイトが役に立ちます。このサイトの式の入力欄に「x^2」と入力するとよいでしょう。もし式(5)を分解しての2乗項との項が混在しているのが不安で本当に最小値をとるは一つに求まるのか僕のように確信が持てない方は上記サイトに「x^2+x」と入力し、xの係数を気が済むまで変更してみるとよいと思います。
に関しての関数である式(5)が最小値をとることはわかりましたが、ではどのように求めるのかというと皆さん大好きな微分を敢行します。微分はあるでのグラフの傾きに相当しますので、最小値をとるでの微分は0になるわけです。式(5)の微分は以下の通りです。
(6) ![\begin{eqnarray*} \begin{split} \frac{dE}{d\vec{w}}&=\frac{1}{d\vec{w}}\left[\frac{1}{2n}\left \{ \left ( y_{1}-\vec{w}^{T}\vec{x}_{1} \right )^{2}+\dots + \left ( y_{n}-\vec{w}^{T}\vec{x}_{n} \right )^{2}\right \}\right]\\ &=\frac{1}{2n}\left \{ 2\left ( y_{1}-\vec{w}^{T}\vec{x}_{1} \right )\left(- \vec{x}_{1}\right )+\dots + 2\left ( y_{n}-\vec{w}^{T}\vec{x}_{n} \right )\left(- \vec{x}_{i}\right )\right \}\\ &=-\frac{1}{n}\sum_{i=1}^{n}\left \{ \left( y_{i}-\vec{w}^{T}\vec{x}_{i}\right ) \vec{x}_{i} \right \} \\ &=-\frac{1}{n}X^{T}\left(\vec{y}-\vec{\hat{y}} \right ) \end{split} \end{eqnarray*}](/wp-content/ql-cache/quicklatex.com-5670983b1e8b293bbe2c28c0dcecf4d6_l3.png "Rendered by QuickLaTeX.com")
式(6)はをちょっと動かしたときの変化量でもあり、グラフの傾きです。最小値をとるの左では微分はマイナスになり、右側では微分はプラスになります。
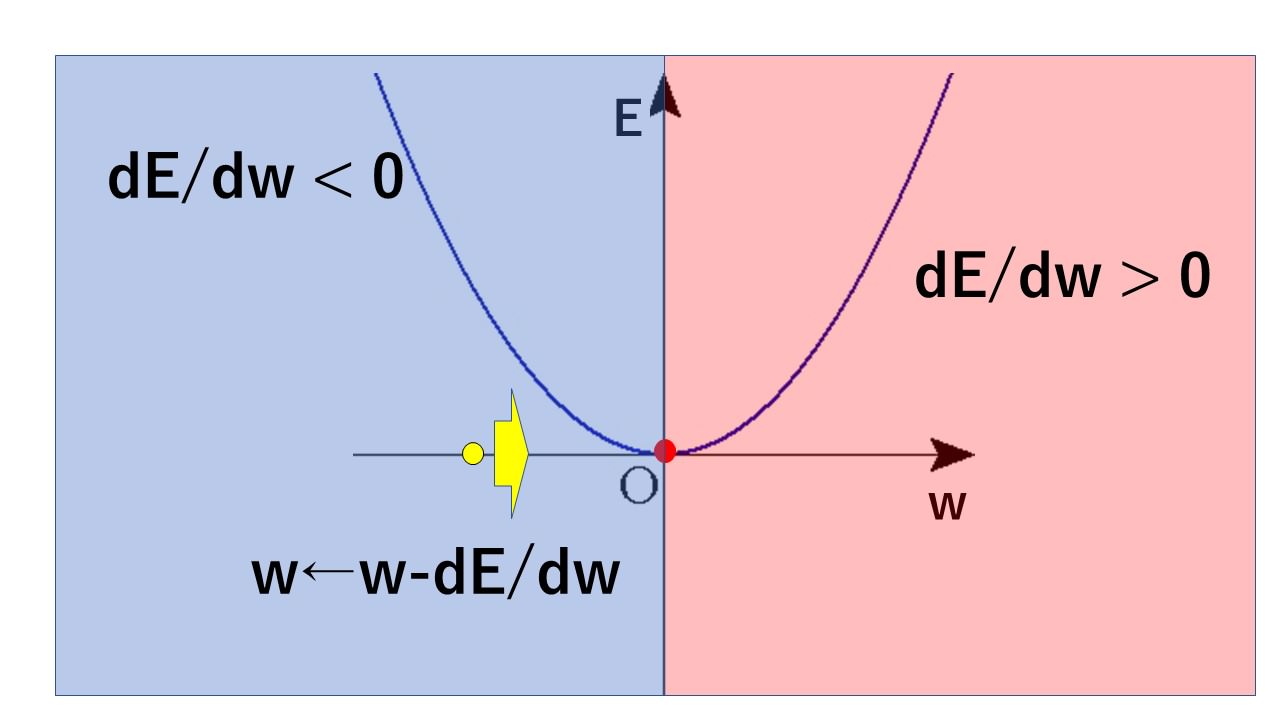
なので適当に決めたに対して式(6)を何度も何度も引き算していくと最小値をとるに収束していく訳ですね。ちょうどボールの中にパチンコ玉を入れたかのように自分で移動していくイメージです。このとき使う式が式(7)です。
(7) 
ここで突然現れた ですが、をいかにちょっとずつ進めるかの度合いになります。を大きくすれば少ない計算量でを収束できますが、答えの精度が落ちることが感覚的にわかりますね。長くなりましたがようやくを求めるための式がわかりました。
ですが、をいかにちょっとずつ進めるかの度合いになります。を大きくすれば少ない計算量でを収束できますが、答えの精度が落ちることが感覚的にわかりますね。長くなりましたがようやくを求めるための式がわかりました。
あとはプログラムに落として計算させてみましょう。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 |
#!/usr/bin/env python3 # -*- coding: utf-8 -*- import numpy as np from sklearn.datasets import load_boston from sklearn.linear_model import LinearRegression from matplotlib import pyplot as plt boston = load_boston() np.random.seed(1234) if __name__ == '__main__': # ###################### 下準備 ######################### # 説明変数:13項目のうち1つだけ使う x = boston.data[:, 5] # 目的変数:住宅価格のデータを使う y = boston.target # ############## 計算式から回帰を実行 #################### # w0の項を追加するためにxに小細工をする large_x = np.array([[1, v] for v in x]) # ランダムな値をw0, w1の初期値に設定する w = np.random.random(len(large_x[0])) # ちょっと変えるための度合いを決める alpha = 0.01 # ------wをちょっとずつ変えていくループを実行------ # ループ回数100回、1000回、10000回、100000回でwを保存する w_100 = [] w_1000 = [] w_10000 = [] for i in range(100000): # 予測値y_hatを計算する。 y_hat = np.dot(large_x, w) # 式2-1 # 損失関数の微分を計算する dw = np.dot((y - y_hat), large_x) / len(large_x) # 式2-5 # wをちょっとだけ動かす # print(i, 'w =', w) w += alpha * dw # 式2-6 if i == 100-1: # listはnp.copyしないとコピー元と同期してしまうので注意! w_100 = np.copy(w) elif i == 1000-1: w_1000 = np.copy(w) elif i == 10000-1: w_10000 = np.copy(w) # ######### skleanのツールLinearRegressionを使って回帰 ########### # ものすごく簡単... lr = LinearRegression(fit_intercept=True) lr.fit(large_x, y) pred = lr.predict(large_x) # ########################### 作図 ############################# # ----------------散布図を作成------------------- plt.scatter(x, y, s=1) # ----------------計算式の結果------------------- plt.plot(x, np.dot(large_x, w_100), label='org_100') plt.plot(x, np.dot(large_x, w_1000), label='org_1000') plt.plot(x, np.dot(large_x, w_10000), label='org_10000') plt.plot(x, np.dot(large_x, w), c='black', linewidth=3.0, label='org_100000') # ---------------sklearnの結果------------------ plt.plot(x, pred, c='y', linestyle='dashdot', label='sklearn') plt.legend() plt.show() |
↓実行結果
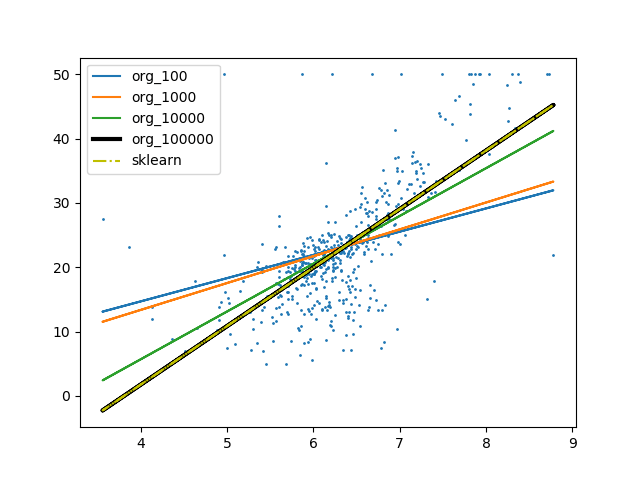
ちょっと動かす回数を変化させて図にしてみましたが、いかがでしょうか。
回数が多くなるにつれ少しずつ「いい感じの線」になってきていることが感覚的にもわかると思います。
最終的に100000回実行した結果はsklearnのツールを使った線と重なっていますので、よい結果が出ているのだと思います。
3.ステータス13項目、全軒分のデータを使う
いよいよステップ3です。
ここまでお付き合いいただいた方はうんざりしているころだと思いますが、安心してください!
ここで使う式(1)は式(4)として既にステップ2で出てきてしまっています!もう式を追わなくてもよいのですよかった!
さて、使う式が同じだというのならステップ2とステップ3はどう違うのでしょうか。
答えはとの中身になります。といってもの量に応じても増えるだけですが。

ここで新たな添え字 が登場しますがこれはに含まれるステータスの数になります。要するにこの場合は13です。
が登場しますがこれはに含まれるステータスの数になります。要するにこの場合は13です。
ステップ3をプログラムに起こすとほぼステップ2と同じですがに値を格納する箇所が異なっていますのでコードを載せておきます。また、使用するステータスが増えましたので「いい感じの線」を作図によって目視することができませんので作図の箇所も不要です。
|
1 2 3 4 5 6 |
# ###################### 下準備 ######################### # 説明変数:13項目の全項目を使う # この時点で小細工をしてしまう large_x = np.array([np.concatenate(([1], v)) for v in boston.data]) |
さて、残念なこと全項目を読み込んでプログラムを実行するとエラーが続発してしまい、うまく計算できなかったのではないでしょうか。
どうやら使用しているステータスのスケールががまちまちだった為、がうまく収束してくれなかった項目があったことが原因のようです。ここでいうスケールというのはあるステータスAは0~1に分布しているのに、ステータスBは100~200に分布していたりすることを指します。個別に回帰するのであればやループ回数を調整してやればよさそうですが、全部の項目に対応できる値となると見当もつきません。。
3.モデルを評価する
前章の最後の最後で手詰まりが起きてしまい、解析がうまくいきませんでしたね!この章では計算結果を評価するはずでしたが……細かいことは気にせずどうにか計算できるようにしてから結果を解析していきましょう。
ステップ3では項目間のスケールの違いがエラーの原因となっていましたのでどうにかしたいものです。こんな時に役に立つのが正規化です。
ここでの正規化というのはデータの平均値からのばらつき(偏差)を、ばらつきの平均値(標準偏差)で割ってやることで、項目間のスケールが違っても平等に評価できるようにする処理を指します。標準化とも呼ばれ、式でいうと以下のようになります。
(8) 
ここで をの平均値、
をの平均値、 を標準偏差といいます。この処理を全項目について適応するには以下のコードを追加します。
を標準偏差といいます。この処理を全項目について適応するには以下のコードを追加します。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
# ###################### 下準備 ######################### # 説明変数:13項目の全項目を使う # この時点で小細工をしてしまう large_x = np.array([np.concatenate(([1], v)) for v in boston.data]) # 目的変数:住宅価格のデータを使う y = boston.target # ---------------- 説明変数を標準化する ----------------- large_x_ = np.mean(large_x, 0) large_xs = np.std(large_x, 0) for i in range(1, len(large_x[0])): large_x[:, i] = (large_x[:, i] - large_x_[i]) / large_xs[i] |
これで何とか無事、を求めることができましたので、さっそく結果の評価をしていきましょう。今回はRMSE(Root Mean Square Error):平均二乗誤差を使って結果を評価していきます。比較対象はライブラリsklearnのツールを使って計算した結果のRMSEです。RMSEは以下の式で計算できます。
(9) 
RMSEは予想した住宅価格と本来の住宅価格の差に関連する値のようですね。予測と実際の値に差異が少なければ0に近づき、差異が大きいほど0から離れていきます。そのためRMSEが小さいほど「いい感じの線」であるといえます。では早速プログラムを使って計算してみましょう!
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 |
import numpy as np from sklearn.datasets import load_boston from sklearn.linear_model import LinearRegression boston = load_boston() np.random.seed(1234) if __name__ == '__main__': # ###################### 下準備 ######################### # 説明変数:13項目の全項目を使う # この時点で小細工をしてしまう large_x = np.array([np.concatenate(([1], v)) for v in boston.data]) # 目的変数:住宅価格のデータを使う y = boston.target # ---------------- 説明変数を標準化する ----------------- large_x_ = np.mean(large_x, 0) large_xs = np.std(large_x, 0) for i in range(1, len(large_x[0])): large_x[:, i] = (large_x[:, i] - large_x_[i]) / large_xs[i] # ############## 計算式から回帰を実行 #################### # ランダムな値をw0, w1の初期値に設定する w = np.random.random(len(large_x[0])) # ちょっと変えるための度合いを決める alpha = 0.01 # ------wをちょっとずつ変えていくループを実行------ # ループ回数100回、1000回、10000回、100000回でy_hatを保存する y_hat =[] y_hat_100 = [] y_hat_1000 = [] y_hat_10000 = [] for i in range(100000): # 予測値y_hatを計算する。 y_hat = np.dot(large_x, w) # 式2-1 # 損失関数の微分を計算する dw = np.dot((y - y_hat), large_x) / len(large_x) # 式2-5 # wをちょっとだけ動かす # print(i, 'w =', w) w += alpha * dw # 式2-6 if i == 100-1: # listはnp.copyしないとコピー元と同期してしまうので注意! y_hat_100 = np.copy(y_hat) elif i == 1000-1: y_hat_1000 = np.copy(y_hat) elif i == 10000-1: y_hat_10000 = np.copy(y_hat) # ######### skleanのツールLinearRegressionを使って回帰 ########### # ものすごく簡単... lr = LinearRegression(fit_intercept=True) lr.fit(large_x, y) pred = lr.predict(large_x) # ######################## RMSEを計算する ######################## # -------------- 計算式の結果のループ回数ごとのRMSE -------------- err_100 = y_hat_100 - y rmse_100 = np.dot(err_100, err_100)/len(y) err_1000 = y_hat_1000 - y rmse_1000 = np.dot(err_1000, err_1000) / len(y) err_10000 = y_hat_10000 - y rmse_10000 = np.dot(err_10000, err_10000) / len(y) err_100000 = y_hat - y rmse_100000 = np.dot(err_100000, err_100000) / len(y) print('rmse_100:', rmse_100) print('rmse_1000:', rmse_1000) print('rmse_10000:', rmse_10000) print('rmse_100000:', rmse_100000) # ----------------- sklearnの結果で計算したRMSE ------------------ err_lr = pred - y rmse_lr = np.dot(err_lr, err_lr) / len(y) print('rmse_lr:', rmse_lr) # 出力結果はこちら # rmse_100: 96.77816336037456 # rmse_1000: 22.148644640929934 # rmse_10000: 21.897780844972825 # rmse_100000: 21.897779217687496 # rmse_lr: 21.897779217687496 |
ループ回数が多ければ多いほど徐々に値が小さくなっていき、10000回を超えたあたりからほぼ値が変わらなくなっています。が収束していっていることが実感できますね。さらに100000回の結果はsklearnで計算した結果とぴたりと同じになっています!
本来はこの結果をもとに良い悪いの評価を行い、データの変更や、モデルの調整を行います。ちょうどこの章の冒頭で行った正規化がデータの変更に対応しています。
まとめ
今回は線形回帰についてまとめてきました。個人的には計算を繰り返すことでが収束していく様子が実感できたのが非常に面白かったです。このが収束する過程が機械学習の学習の部分です。sklearnに代表されるツールは便利ですが、実際に数式をコードに落とし込む工程は勉強になることが多く苦労する価値はあると感じています。
軽い気持ちで書いてきた今回の記事ですが、長文になってしまいました。ここまでお付き合いいただいた方はありがとうございます。線形回帰で躓いている方の助けになれば幸いです!