

はじめに
BERTとは、自然言語処理に使われる汎用言語モデルの名前である。Googleが2018年に発表した(原論文)。このモデルをファインチューニングすることにより、自然言語処理の多くのタスクでSOTA(State Of The Art)が達成されている。今回はこのBERTを用いた文書分類を、既存コードとライブラリを用いて行う。
問題設定
以下の問題を考える。
- 文書を複数個用意する。各文書はタイトルと本文(document)から成る。ここで、本文とは文(sentence)の集まりのことである。
- 文書は複数の分野から集める。
- タイトルあるいは本文だけからその分野を予測したい。
最初に、タイトルによる分類(タイトル分類)を考える。
タイトル分類の方針
タイトルを1つの文とみなし、これをBERTを用いて1つの多次元ベクトル(文埋め込み:sentence embeddings)に変換する。分野をラベルと見なせば、単純な多分類問題に帰着する。今回はSVM(liblinear)を用いて分類を行う。
文埋め込み(sentence embeddings)の導出
こちらのページに記載されている手順を踏襲する。このページでは、京都大学の黒橋・河原研究室が最近公開した「BERT日本語Pretrainedモデル」を用いた文埋め込みの導出手順が紹介されている。ソースコードも公開されているので、これを利用する。
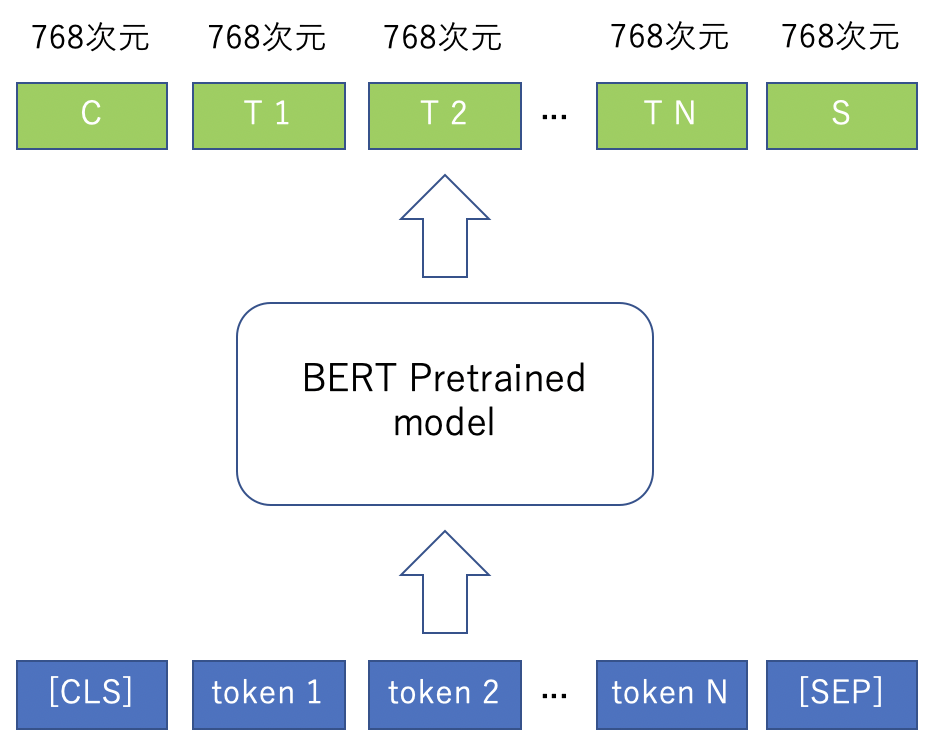
紹介されている手順は以下の通り(下図参照)。
- 文をJuman++(トークナイザー)でトークンに分解する。
- 文頭に[CSL]を、文末に[SEP]を付加する。これらはあらかじめ定義されたトークンである。前者は文頭であることを、後者は文末であることを表す。
- 出来上がったトークンを訓練済みモデルに入力する。
- モデルの出力は、入力トークン数と同じ個数の768次元ベクトルである。
次に、N+2個の768次元ベクトルを、各次元ごとに操作opを適用することにより、1つのベクトルに集約する(下図参照)。
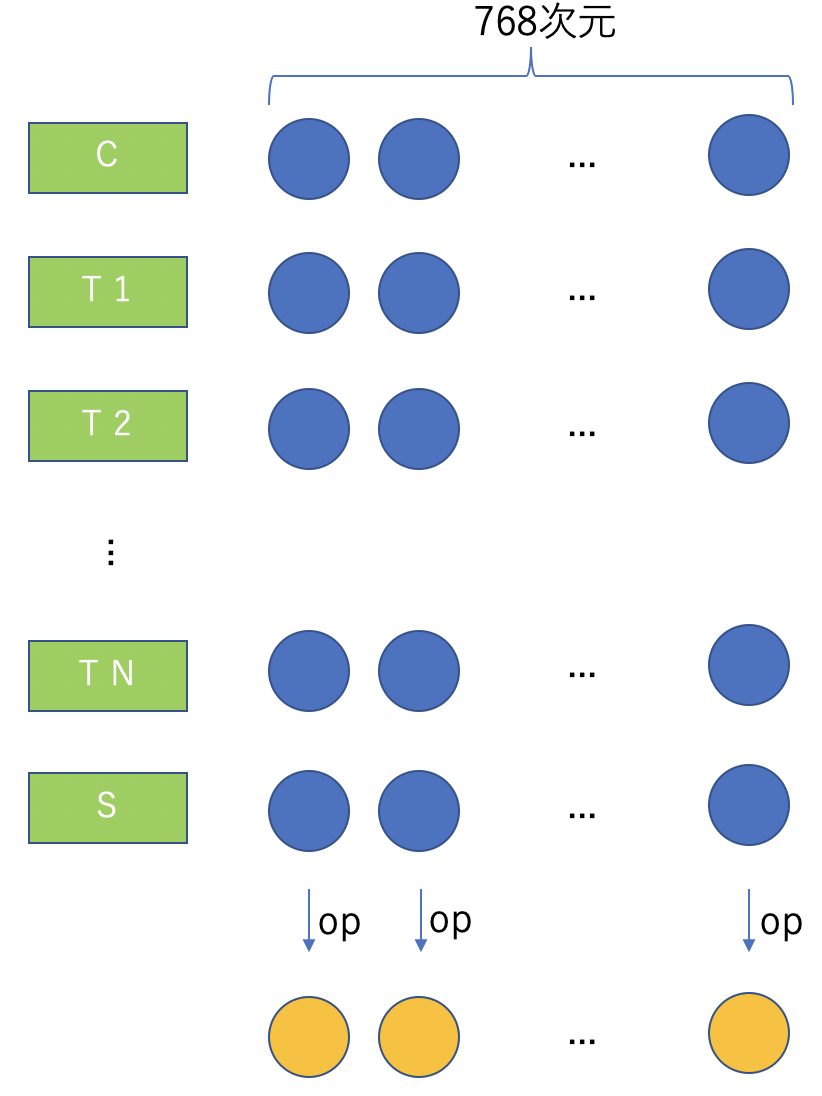
操作opとして次の3つが実装されている。
順にop:max、op:mean、op:mean_maxと呼ぶことにする。mean_maxは平均ベクトルと最大値からなるベクトルを結合したものである。また、入力トークン[CLS]に相当する出力Cをもって文を代表させる方法も提供されている。この操作をop:clsとする。
データセット
今回はlivedoorニュースコーパスを利用する。このコーパスでは、9つの分野から文書が集められている。
- 独女通信(dokujo-tsushin)
- ITライフハック(it-life-hack)
- 家電チャンネル(kaden-channel)
- livedoor HOMME(livedoor-homme)
- MOVIE ENTER(movie-enter)
- Peachy(peachy)
- エスマックス(smax)
- Sports Watch(sports-watch)
- トピックニュース(topic-news)
ある文書の中身は以下のようになっている。

1行目は記事のURL、2行目は記事の日付、3行目は記事のタイトル、4行目以降は記事の本文である。ここでは3行目だけを利用する。分野は9つなので9分類問題である。
タイトル分類の結果
SVM(liblinear)の訓練コマンドはオプション「-s」を取る。このオプションには0から7までの整数値を渡せる(詳細はここ)。そのうち0(L2正則化項+ロジスティック回帰)と2(L2正則化項+L2損失項)に対しては、ハイパーパラメータを最適化することができる。0と2の場合の結果を以下に示す。
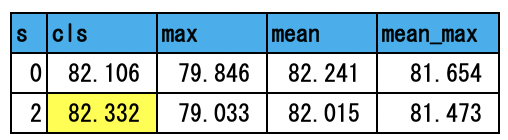
最も精度が良いものを黄色で示した。およそ82.3%程度である。分野を「ITライフハック」、「MOVIE ENTER」、「Sports Watch」の3つに絞ると以下の結果を得た。
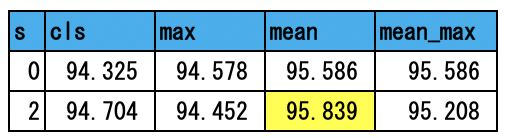
およそ95.8%である。
タイトル分類のソースコード
ソースコードはここにある。
次に本文を用いた分類(本文分類)を行なう。
本文分類の方針
上で示したように本文は文書の4行目以降である。4行目以降を抜き出し、以下の作業を行なう。
- 本文は複数の文から構成される。いまN個の文があるとする。
- 最初に各文を文埋め込み(sentence embeddings)に変換する。このとき操作op:clsを用いる。
- この手順のあと、N個の768次元ベクトルが出来上がる。これらから1つの768次元ベクトルを作成する(下図参照)。
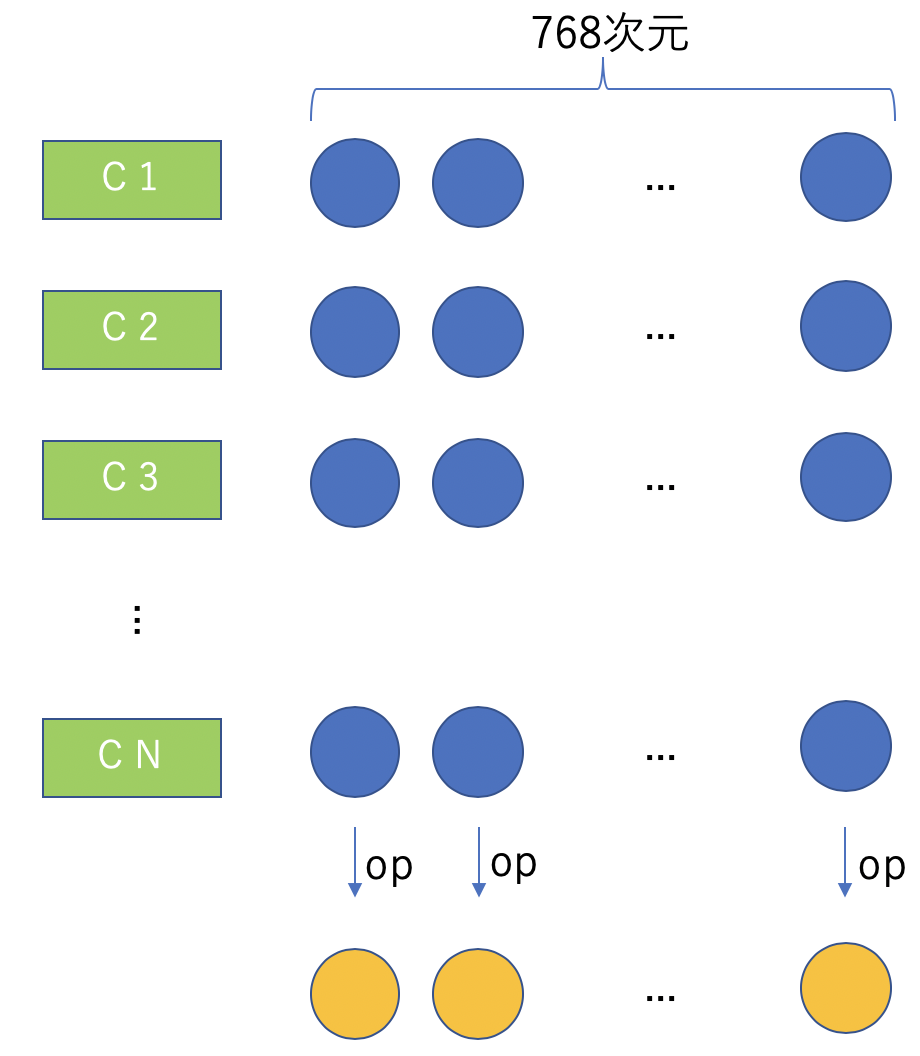
ここで用いる操作は、op:max、op:mean、op:mean_maxの3つである。
本文分類の結果
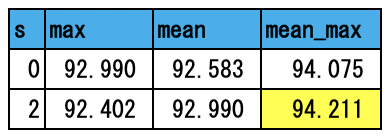
先と同じようにSVM(liblinear)を用いて分類を行う。最初に9分類の結果を示す。
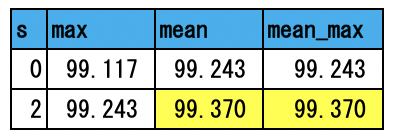
分野を「ITライフハック」、「MOVIE ENTER」、「Sports Watch」の3つに絞ると以下の結果を得た。
本文分類のソースコード
ソースコードはここにある。
まとめ
今回は、京大黒橋・河原研が公開しているBERT訓練済みモデルを用いて文書分類を行ってみた。最初にタイトルから分野を予測するタイトル分類を行い、その精度は82%(9分類)と95.8%(3分類)となった。次に本文から分野を予測する本文分類を行い、94.2%(9分類)と99.4%(3分類)という精度を得た。いずれもかなり良い精度である。特に本文分類の3分類では99.4%という驚異的な結果となっている。BERTのロジックの良さだけでなく、それを日本語に適した形態素解析の下で訓練したモデルのおかげであろう。