

こんにちはtetsuです。
今回は、人間が頑張って試行錯誤しなくとも、高精度なディープラーニングのモデルを寝てる間にでも自動で生成できたらいいなぁという願望を叶えることができるかもしれないAuto-Kerasについてご紹介します。特に、画像分類の実験を通してAuto-Kerasの使い方とその結果について説明します。
Auto-Kerasとは?
Auto-KerasはテキサスA&M大学の方が中心となって開発しているオープンソースのライブラリになります。使う側が学習データを用意し、Auto-Kerasに学習データを与えることで、精度の良いディープラーニングのモデルのネットワーク構造とハイパーパラメータを探索してくれます。Auto-Kerasのように学習データと解きたい問題の種類(回帰、分類、ランク学習など)を与えると、良いモデルのネットワーク構造を探すような手法をNeural Architecture Searchといいます。
この記事を書いている2019/3/7現在はRNN(Recurrent Neural Network)はサポートされていませんが、CNN(Convolutional Neural Network)はサポートされており、CNNを使った画像分類やテキスト分類のためのネットワーク構造の探索ができます。
Auto-Kerasという名前から、中身は主にKerasが使われていると思っていたのですが、コードをみるとPyTorchがよく使われています。ただし、生成したモデルをKerasのモデルとして保存することが可能となっています。
Auto-Kerasの導入
Ubuntu16.04で試したところ、以下のようにして問題なくインストールできました。
|
1 |
$ pip install autokeras |
PyTorchやTensorFlowなどのライブラリがインストールされるので、少し時間がかかります。
Auto-Kerasを用いた実験
Auto-Kerasを使って画像分類問題を解くためのモデルを生成するときのコードと実験の結果を示していきます。なお、実験にはAuto-Kerasの0.3.7を用いています。またモデルの学習時にはNVIDIA社のGPUのGeForce GTX 1080を用いています。
データセット
実験ではKuzushiji-MNISTというデータセットを使うことにします。
このデータセットは古い書物から10種類のくずし字のひらがなを集めたものです。よく使われるデータセットとして、0~9の手書き数字の画像を集めたMNISTがありますが、それの日本語版のようなものです。例えば以下のような文字がデータセットに含まれます。

皆さんは読めるでしょうか?残念ながら私にはあまり読めません。
Kuzushiji-MNISTのページの下の方を見ると、このデータセットに対してディープラーニングのモデルで98.90%のaccuracy(モデルの予測の正解率)が出たという記録が載っていますので、Auto-Kerasを使って98%程度のaccuracyになると良いなという期待をして次の実験に進みます。
Auto-Kerasの使い方とモデルの性能
Auto-Kerasによってモデルのネットワーク構造とハイパーパラメータの探索をおこなうコードは以下のようになります。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
import numpy as np from autokeras.image.image_supervised import ImageClassifier x_train = np.load('/opt/data/kuzushiji/kmnist-train-imgs.npz')['arr_0'] x_test = np.load('/opt/data/kuzushiji/kmnist-test-imgs.npz')['arr_0'] x_train = x_train.reshape(x_train.shape + (1, )) x_test = x_test.reshape(x_test.shape + (1, )) y_train = np.load('/opt/data/kuzushiji/kmnist-train-labels.npz')['arr_0'] y_test = np.load('/opt/data/kuzushiji/kmnist-test-labels.npz')['arr_0'] clf = ImageClassifier(verbose=True) clf.fit(x_train, y_train, time_limit=12 * 60 * 60) |
学習に使いたいデータを読み込んで、それをAuto-Kerasのfitメソッドに渡しているだけです。fitメソッドでネットワーク構造とハイパーパラメータの探索をおこなっていますが、time_limitが探索をおこなう時間の上限になります。単位は秒なので、上記の例では12時間です。
fitの内部では、渡したデータ(コード中のx_trainとy_train)を学習用と検証用に分けて使用しています。また画像の分類問題では、通常は入力する画像の正規化をおこないますが、これも内部で自動的におこなっています。
一番良いモデルのネットワーク構造とハイパーパラメータが見つかったら、それらを使って再度学習をおこないます。ただし、先ほどのfitとは異なり、x_trainとy_trainを学習用と検証用に分割せずにそのまま学習に使用することで、データを有効活用します。final_fitでこれをおこなうことができます。また、final_fitで得られたモデルはAuto-KerasかKerasで読み込める形で保存できます。final_fitとモデルを保存するコードは次のようになります。
|
1 2 3 |
clf.final_fit(x_train, y_train, x_test, y_test, retrain=True) clf.export_autokeras_model("./autokeras_model.bin") # Auto-Kerasで読み込めるモデルを保存 clf.export_keras_model("./keras_model.bin") # Kerasで読み込めるモデルを保存 |
次にfinal_fitで得られたモデルのaccuracyを計算してみます。
|
1 |
acc = clf.evaluate(x_test, y_test) |
上記を実行した結果、テストデータのaccuracyは98.64%でした。98.90%には至りませんが、それに近い性能となっています。
今回の実験では12時間で50モデル生成することができました。これらのモデルの検証用データでのaccuracyの変化を次のようにプロットしました。
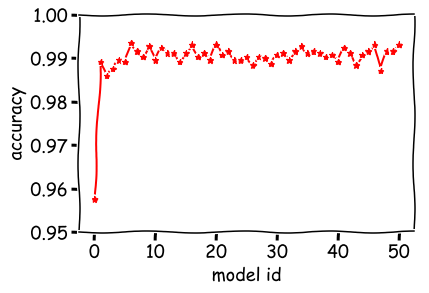
横軸のmodel idが小さいものから順にモデルが生成されています。1個目のモデルは96%程度のaccuracyですが、2個目のモデルからは99%前後となっています。12時間で50モデル作りましたが、10モデル作れば十分だったかもしれません。
Auto-Kerasで得られたモデルの構造
Kerasのモデルとして読み込んで、モデルのネットワーク構造を確認したいと思います。次のようにしてネットワーク構造を描画しました。
|
1 2 3 4 5 |
from tensorflow import keras from keras.utils import plot_model model = keras.models.load_model("./keras_model.bin") plot_model(model, to_file='model.png') |
上記のコードを実行した結果、次の画像が生成されます。

それなりに深いネットワークで、とても縦長になってしまいました。
ネットワークの中身をみると、Residual Networkで使われているResBlockの存在が確認できます。Auto-Kerasの内部ではResBlockやDenseBlockが定義されていますので、その中から選ばれてきたようです。
終わりに
今のところは適用できるタスクが限られていますが、画像の分類や回帰の場合にはAuto-Kerasを使って楽をするのも良いかもしれませんね。