

こんにちは、エンジニアのtetsuです。
Pythonで機械学習をおこなう人はAnacondaを使っている方も多いのではないのでしょうか。
Anacondaを使えば、一発でNumPyやscikit-learn、Matplotlib、Pandasといった便利なライブラリを導入することができるので人気なのもうなずけます(一方で不便な面もありますが)。しかしながら、Anacondaを使うメリットはそれだけではありません。
NumPyで呼び出される行列演算を実際に担うBLAS (Basic Linear Algebra Subprograms)というものには様々な実装法が存在しているのですが、その一つがIntel社が開発しているIntel MKL(Math Kernel Library)となります。実はAnacondaによってインストールされたNumPyから呼び出されるBLASはMKLになっていますが、pipでNumPyをインストールした場合には通常はOpenBLASというBLASが使われるため、ここで性能に差が出る可能性があるわけです。
今回はこれらの速度の違いについてみていきます。
BLASの確認
速度比較に移る前に、使用しているNumPyの中ではどのBLASが呼ばれているかを確認しましょう。
確認は簡単で、次の2行で済みます。
|
1 2 |
import numpy as np np.show_config() |
MKLが使われているNumPyの場合には次のような出力になります。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
mkl_info: libraries = ['mkl_rt', 'pthread'] library_dirs = ['/opt/conda/lib'] define_macros = [('SCIPY_MKL_H', None), ('HAVE_CBLAS', None)] include_dirs = ['/opt/conda/include'] blas_mkl_info: libraries = ['mkl_rt', 'pthread'] library_dirs = ['/opt/conda/lib'] define_macros = [('SCIPY_MKL_H', None), ('HAVE_CBLAS', None)] include_dirs = ['/opt/conda/include'] blas_opt_info: libraries = ['mkl_rt', 'pthread'] library_dirs = ['/opt/conda/lib'] define_macros = [('SCIPY_MKL_H', None), ('HAVE_CBLAS', None)] include_dirs = ['/opt/conda/include'] lapack_mkl_info: libraries = ['mkl_rt', 'pthread'] library_dirs = ['/opt/conda/lib'] define_macros = [('SCIPY_MKL_H', None), ('HAVE_CBLAS', None)] include_dirs = ['/opt/conda/include'] lapack_opt_info: libraries = ['mkl_rt', 'pthread'] library_dirs = ['/opt/conda/lib'] define_macros = [('SCIPY_MKL_H', None), ('HAVE_CBLAS', None)] include_dirs = ['/opt/conda/include'] |
またOpenBLASが使われていれば次のようになるでしょう。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
blas_mkl_info: NOT AVAILABLE blis_info: NOT AVAILABLE openblas_info: libraries = ['openblas', 'openblas'] library_dirs = ['/usr/local/lib'] language = c define_macros = [('HAVE_CBLAS', None)] blas_opt_info: libraries = ['openblas', 'openblas'] library_dirs = ['/usr/local/lib'] language = c define_macros = [('HAVE_CBLAS', None)] lapack_mkl_info: NOT AVAILABLE openblas_lapack_info: libraries = ['openblas', 'openblas'] library_dirs = ['/usr/local/lib'] language = c define_macros = [('HAVE_CBLAS', None)] lapack_opt_info: libraries = ['openblas', 'openblas'] library_dirs = ['/usr/local/lib'] language = c define_macros = [('HAVE_CBLAS', None)] |
MKLとOpenBLASの速度比較
速度比較の準備
今回は2つのBLASに対して次の計算の速度を測ってみます。
- 行列の要素同士の積
- 行列積
- 行列 + ベクトル(ブロードキャスト)
- 行列の特異値分解
- 行列の固有値分解
- 連立一次方程式の求解
計算に使われる行列はすべて一様乱数によって生成された のサイズの実数の正方行列です。ベクトルについても同様に一様乱数によって生成された
のサイズの実数の正方行列です。ベクトルについても同様に一様乱数によって生成された 次元の実数のベクトルとしました。
次元の実数のベクトルとしました。
計算時間の計測にはipythonの%%timeitを使っています。
NumPyのバージョンはそれぞれ1.15.1で計算機のCPUはIntel(R) Core(TM) i7-7700 CPU @ 3.60GHzであり、4コアが載っています。
MKLとOpenBLASの速度比較の結果
計測した計算時間の平均を次の図に示します。特異値分解と固有値分解は他の計算時間と桁が大きく違うのでグラフを分けています。
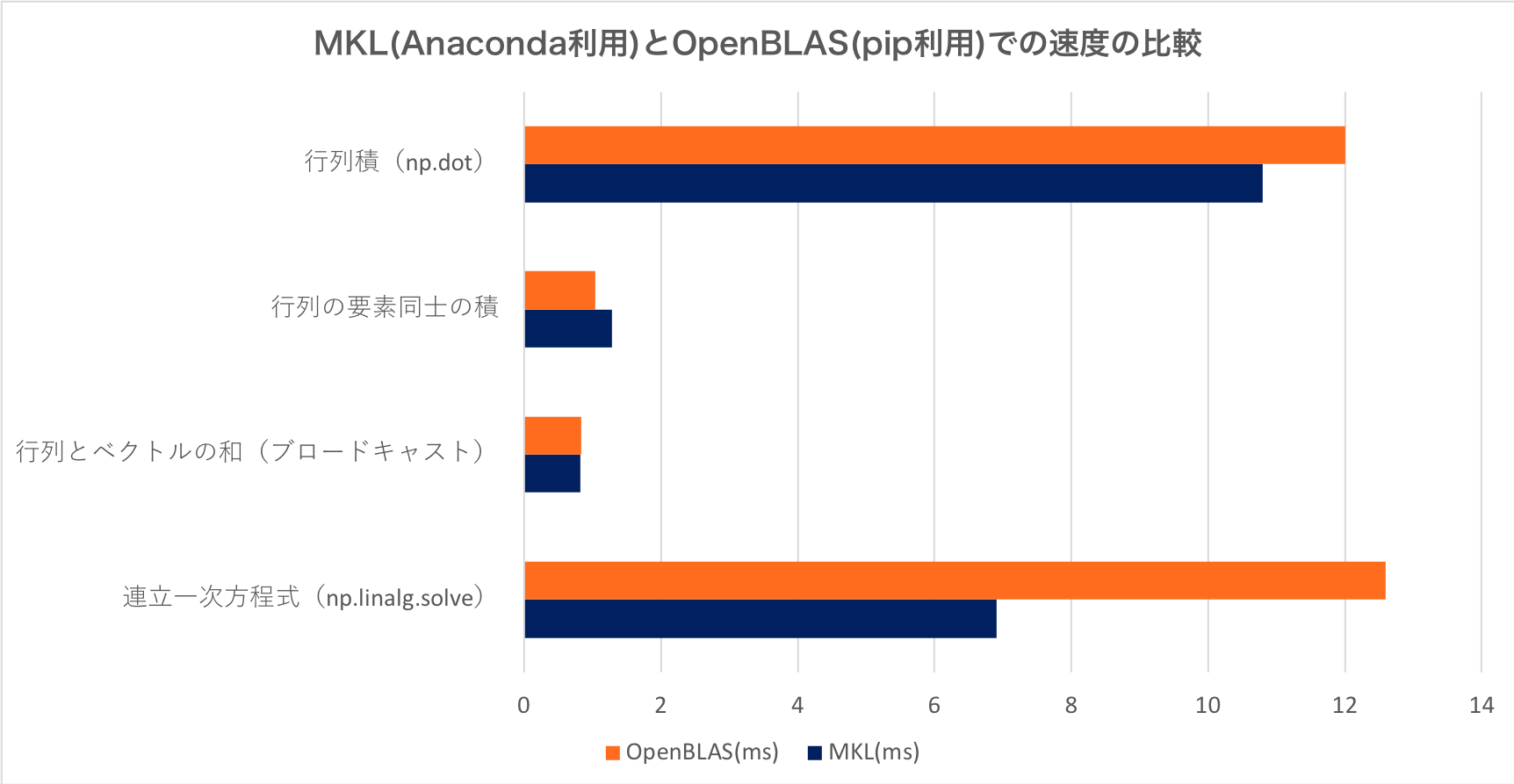
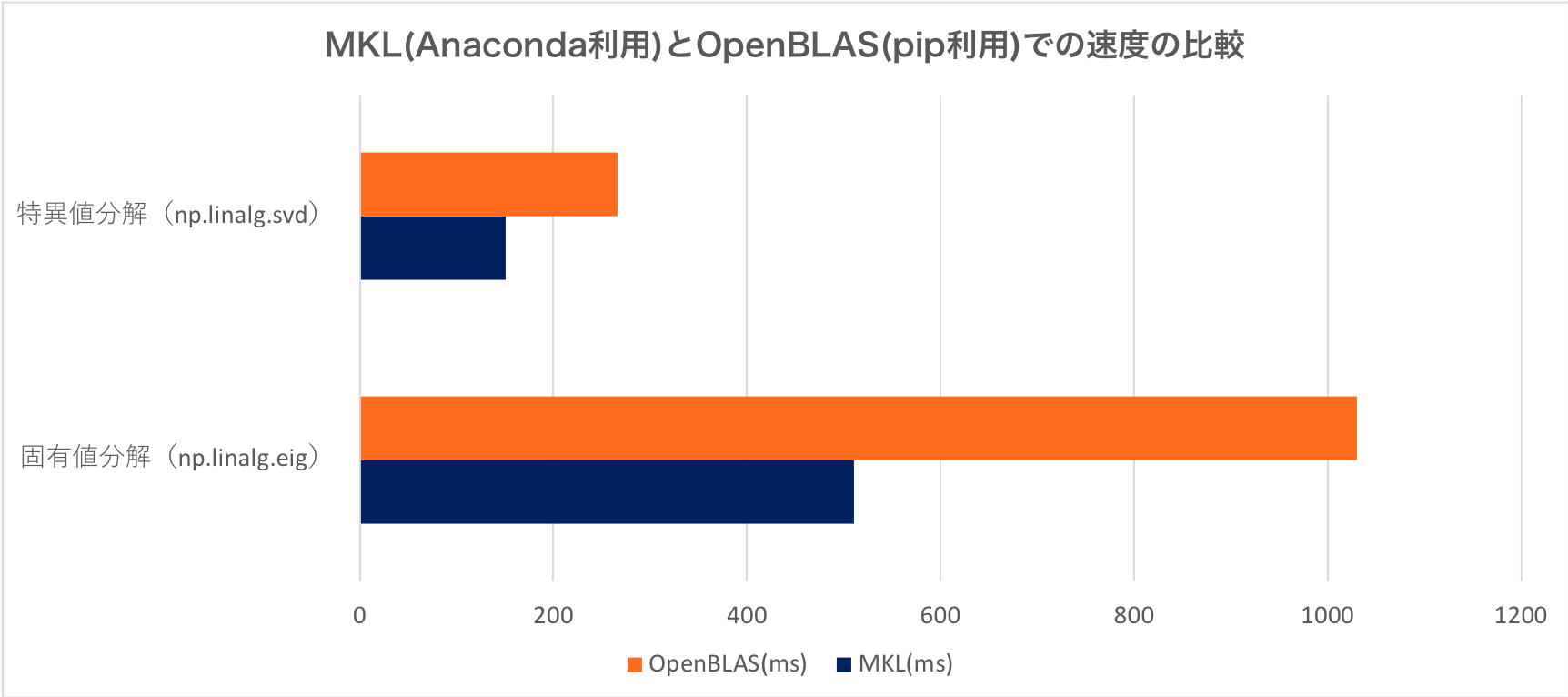
結果をみると、行列の要素同士の積に関してはOpenBLASのほうが高速ですが、他に関してはすべてMKLのほうが速いです。特に特異値分解や固有値分解は大分速いですね!2倍近く速いのは驚きますね。
行列のサイズやCPUのコアの数でも傾向が変わるかもしれませんが、その辺の話についてはfuture workということでお願いします。
終わりに
今回はAnacondaでNumPyをインストールしたときとpipでNumPyをインストールしたときでの差についてお話しました。
従来の機械学習手法では特異値分解や固有値分解をおこなうケースも多々ありますのでスピードが気になったら、MKLを使うことを検討するのもいいかと思います。