

はじめに
今回は、C++でOpenCVのcv::Matを使う際の小ネタ集である。以下の小ネタを扱う。
- 画素へのアクセス
- BGRの謎
- 演算子のオーバーロード
- ROIの抽出
- Blobの作成
cv::Matとは、画像を保持する2 2の行列を表すクラスである。
2の行列を表すクラスである。
検証環境
- OS: Windows11 Pro
- プロセッサ: Intel(R) Core i7 2.80 GHz
- RAM: 16GB
1. 画素へのアクセス
最初に取り上げる話題は画素へのアクセスの仕方だ。画像の各画素にアクセスする方法として次の3つを考えることができる。
- atメソッドを使う。
- ポインタを使う。
- イテレータを使う。
順にサンプルコードを見ていく。
atメソッドを使う
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 |
// // atを用いた実装 void method_at(const cv::Mat& image) { const auto rows = image.rows; const auto cols = image.cols; // 出力画像を作成 auto target = cv::Mat{ rows, cols, CV_8UC3, cv::Scalar{0, 0, 0} }; for (auto j = 0; j < rows; ++j) { for (auto i = 0; i < cols; ++i) { // ピクセルにアクセス const cv::Vec3b& pixel = image.at<cv::Vec3b>(j, i); // j行目、i列目の画素を取得 // 色成分を取得 uchar blue = pixel[0]; uchar green = pixel[1]; uchar red = pixel[2]; // 色成分を変更 uchar new_blue = blue / 2; uchar new_green = green / 2; uchar new_red = red / 2; // ピクセルを更新 target.at<cv::Vec3b>(j, i) = cv::Vec3b(new_blue, new_green, new_red); } } } |
4行目と5行目で入力画像の行数rowsと列数colsを取得している。8行目で出力画像を格納する箱を用意する。CV_8UC3は符号なし8ビット・3チャンネルを指定する識別子である。ループの中では全画素値の置き換えをしている。13行目と26行目でcv::Matのatメソッドを使っている。atメソッドの呼び出しごとに境界チェック(画像外をアクセスしていないか)が行われるため、実行速度は遅くなる。
ポインタを使う
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 |
// // pointerを用いた実装 void method_pointer(const cv::Mat& image) { const auto rows = image.rows; const auto cols = image.cols; auto target = cv::Mat{ rows, cols, CV_8UC3, cv::Scalar{0, 0, 0} }; for (auto j = 0; j < rows; ++j) { const cv::Vec3b* row = image.ptr<cv::Vec3b>(j); // j行目の先頭ポインタを取得 cv::Vec3b* target_row = target.ptr<cv::Vec3b>(j); // j行目の先頭ポインタを取得 for (auto i = 0; i < cols; ++i) { const cv::Vec3b& pixel = row[i]; // j行目、i列目の画素を取得 // 色成分を取得 uchar blue = pixel[0]; uchar green = pixel[1]; uchar red = pixel[2]; // 色成分を変更 uchar new_blue = blue / 2; uchar new_green = green / 2; uchar new_red = red / 2; // ピクセルを更新 target_row[i] = cv::Vec3b(new_blue, new_green, new_red); } } } |
cv::Matのptrメソッドを使い、9行目で入力画像のポインタを、10行目で出力画像のポインタを取得している。この2つのポインタはどちらもj行目の画像の先頭を指す。12行目と25行目でi列目の画素値にアクセスしている。ループの中でしていることはatメソッドのときと同じである。アクセス時に境界チェックは行われないので高速である。ただし、画像のメモリレイアウトを正確に把握しておく必要がある。
イテレータを使う
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 |
// // iteratorを用いた実装 void method_iterator(const cv::Mat& image) { const auto rows = image.rows; const auto cols = image.cols; auto target = cv::Mat{ rows, cols, CV_8UC3, cv::Scalar{0, 0, 0} }; auto src_it = image.begin<cv::Vec3b>(); auto dst_it = target.begin<cv::Vec3b>(); auto src_end = image.end<cv::Vec3b>(); while (src_it != src_end) { const cv::Vec3b& pixel = *src_it; // 色成分を取得 uchar blue = pixel[0]; uchar green = pixel[1]; uchar red = pixel[2]; // 色成分を変更 uchar new_blue = blue / 2; uchar new_green = green / 2; uchar new_red = red / 2; // ピクセルを更新 *dst_it = cv::Vec3b(new_blue, new_green, new_red); ++src_it; ++dst_it; } } |
8行目から10行目でcv::Matのbeginメソッドとendメソッドを使いイテレータを取得している。これを使い左上から右下に向けて直線的に画素にアクセスする。イテレータの場合はatメソッドの時と同様に境界チェックが行われるためオーバヘッドがある。
速度比較
30003000の画像の全画素の更新を100回行い平均を取った処理速度は以下の通り。予想通りポインタ版が最も速い。イテレータ版が最も遅いのは少し意外であった。
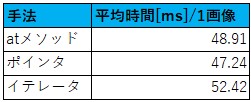
図1
2. BGRの謎
次の話題は「なぜOpenCVの画素の並びはRGBではなくBGRなのか」だ。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
// int main(int argc, char* argv[]) { const auto IMAGE_PATH = std::string{"C:/data/cct_blog/opencv_koneta/icelandlake2540.jpg"}; const auto image = cv::imread(IMAGE_PATH); cv::Vec3b pixel = image.at<cv::Vec3b>(0, 0); // B,G,Rの順に入っている。 uchar blue = pixel[0]; uchar green = pixel[1]; uchar red = pixel[2]; return 0; } |
9行目から11行目でBGRの順に値を取り出している。この並びである理由の1つとして、OpenCVの前身であるIPL(Image Processing Library)での並びがBGRであったためであると言われている。IPLはもともとWindows用であり、Windowsでは内部画像形式としてDIB(Device Independent Bitmap)が使われていた。DIBの画素の並びはBGRである。他にもいろいろな説があるので興味がある方はこちらを参照してほしい。
3. 演算子のオーバーロード
次の話題は演算子のオーバーロードである。以下のコードに見るようにcv::Matのインスタンスを普通の数字のように使い四則演算を行うことができる。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
// int main(int argc, char* argv[]) { auto x = cv::Mat{ 2, 2, CV_32FC1, cv::Scalar{1} }; auto y = cv::Mat{ 2, 2, CV_32FC1, cv::Scalar{2} }; // + { auto z = x + y; std::cout << "+ : " << z << std::endl; } // - { auto z = x - y; std::cout << "- : " << z << std::endl; } // * { auto z = x * y; std::cout << "* : " << z << std::endl; } return 0; } |
3行目と4行目で22行列xとyを作成している。xの成分は全て1に、yの成分は全て2に初期化している。6行目以降に示した3つの演算子「+」「-」「*」の実装には式テンプレート(Expression Template)という手法が使われる。この手法は、式全体を1つのオブジェクトとして表現し、実際に計算が必要になるまでその評価を遅らせる方法である(遅延評価と呼ばれる)。上の例で言えば、9行目、15行目、21行目で初めて数値を用いた計算が実行される。演算「*」は行列同士の積である。出力結果は以下の通り。
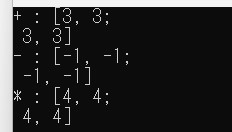
図2
このテクニックにより、計算の過程で発生する一時オブジェクトの生成を避けることができ、パフォーマンスの向上を期待できる。上のコードに挙げた例以外に、割り算(/)や各種不等号もサポートされる。サポートされる演算の一覧はこちらのAPIドキュメントを見てほしい。
4. ROIの抽出
次の話題はROI(Region Of Interest)の抽出である。画像内の任意の矩形領域を抽出する処理である。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 |
// void fill_with_black(cv::Mat& roi); int main(int argc, char* argv[]) { const auto IMAGE_PATH = std::string{"C:/data/cct_blog/opencv_koneta/Parrots.bmp"}; auto image = cv::imread(IMAGE_PATH); const auto rows = image.rows; const auto cols = image.cols; std::cout << std::format("rows:{}, cols:{}", rows, cols) << std::endl; auto x = cols / 2; auto y = rows / 2; auto width = 50; auto height = 50; auto rect = cv::Rect(x, y, width, height); // ROIの抽出(コピーではなく参照である) auto roi = image(rect);// .clone(); // ROIを真っ黒にする。 fill_with_black(roi); cv::imshow("image", image); cv::imwrite("C:/data/cct_blog/opencv_koneta/Parrots_roi.jpg", image); cv::waitKey(0); return 0; } void fill_with_black(cv::Mat& roi) { const auto rows = roi.rows; const auto cols = roi.cols; for (auto j = 0; j < rows; ++j) { cv::Vec3b* row = roi.ptr<cv::Vec3b>(j); // j行目の先頭ポインタを取得 for (auto i = 0; i < cols; ++i) { const cv::Vec3b& pixel = row[i]; // j行目、i列目の画素を取得 // ピクセルを更新 row[i] = cv::Vec3b(0, 0, 0); } } } |
18行目でROIを抽出し変数roiに代入している。抽出される画像内の場所は11行目から15行目で指定される。roiは画像内の矩形領域のコピーでなく参照であるため、21行目でこの領域を黒く塗りつぶすと元画像imageの対応する領域も黒になる。図2の左は黒く塗りつぶす前の画像、右はroiを黒く塗りつぶした後のimageである(画像はこちらからダウンロードした)。

図2
参照ではなくコピーが欲しい場合は、18行目の右辺をimage(roi).clone()とすれば良い。
5. Blobの作成
最後の話題は、深層学習の入力(Blobと呼ばれる)についてだ(OpenCVを用いた深層学習については前回のブログで解説した)。深層学習の入力は普通の画像とは異なる形式でcv::Matに格納される。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 |
// int main(int argc, char* argv[]) { // blobに設定したい画像 const auto IMAGE_PATH = std::string{"C:/data/cct_blog/opencv_koneta/icelandlake2540.jpg"}; // カラー画像を読み込む cv::Mat originalImage = cv::imread(IMAGE_PATH, cv::IMREAD_COLOR); if (originalImage.empty()) { std::cerr << "Error: Image not found." << std::endl; return -1; } std::cout << std::format("rows: {}", originalImage.rows) << std::endl; // 1440 std::cout << std::format("cols: {}", originalImage.cols) << std::endl; // 2560 std::cout << std::format("channels: {}", originalImage.channels()) << std::endl; // 3 // blobFromImage を使って画像から blob を作成 // パラメータは適宜調整する。 double scalefactor = 1.0; // スケールファクター cv::Size size = cv::Size(originalImage.cols, originalImage.rows); // 入力サイズ cv::Scalar mean = cv::Scalar(0, 0, 0); // 平均減算の値 bool swapRB = true; // OpenCV は BGR 形式で読み込むため、通常は swapRB = true に設定 auto originalImages = std::vector<cv::Mat>{ originalImage, originalImage.clone() }; auto inputBlob = cv::dnn::blobFromImages(originalImages, scalefactor, size, mean, swapRB, false); std::cout << std::format("dim: {}", inputBlob.dims) << std::endl; // 4 std::cout << std::format("batch size: {}", inputBlob.size[0]) << std::endl; // 2 std::cout << std::format("channels: {}", inputBlob.size[1]) << std::endl; // 3 std::cout << std::format("height: {}", inputBlob.size[2]) << std::endl; // 1440 std::cout << std::format("width: {}", inputBlob.size[3]) << std::endl; // 2560 std::cout << std::format("rows: {}", inputBlob.rows) << std::endl; // -1が出る。無効な値 std::cout << std::format("cols: {}", inputBlob.cols) << std::endl; // -1が出る。無効な値 std::cout << std::format("channels: {}", inputBlob.channels()) << std::endl; // 1が出る。無効な値 auto height = inputBlob.size[2]; auto width = inputBlob.size[3]; auto redImage = cv::Mat{ height, width, CV_32F, inputBlob.ptr<float>(0, 0) }; auto greenImage = cv::Mat{ height, width, CV_32F, inputBlob.ptr<float>(0, 1) }; auto blueImage = cv::Mat{ height, width, CV_32F, inputBlob.ptr<float>(0, 2) }; // 画像を正しい形式に変換 (CV_32F -> CV_8U) redImage.convertTo(redImage, CV_8U, 1.0); // スケーリング greenImage.convertTo(greenImage, CV_8U, 1.0); // スケーリング blueImage.convertTo(blueImage, CV_8U, 1.0); // スケーリング // カラー画像へ auto channels = std::vector<cv::Mat>{ blueImage, greenImage, redImage }; auto colorImage = cv::Mat{}; cv::merge(channels, colorImage); // 画像を表示 cv::imshow("Input Blob Image", colorImage); cv::waitKey(0); return 0; } |
7行目作られるcv::MatのインスタンスoriginalImageは通常のフォーマットで画像を格納する。13行目から15行目で高さ、幅、チャンネル数を表示している。20行目から25行目でBlobを作成する準備をし、26行目のcv::dnn::blobFromImagesでBlobinputBlogを作成している。Blogの情報は28行目から32行目のようにして取得する。inputBlob.sizeの中に(batch_size,channels,height,width)の順に格納されている。bach_sizeが2となる理由は、25行目で2枚の画像を与えているからである。通常の画像のように情報を取得すると(34 行目から36行目)無効な値が返るので注意が必要である。画像1枚のときのメモリレイアウトを図3に示す。
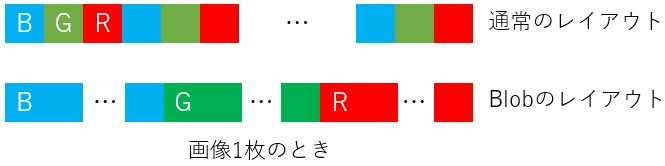
図3
3つのチャンネルが別々に格納されているので、通常のレイアウトに戻すには、38行目から52行目のようにひと手間が必要である。画像表示関数cv::imshow(55行目)に渡せるのは通常のレイアウトを持つcv::Matだけである。
まとめ
今回は、C++で書く時のOpenCVの小ネタを集めた。コピーや参照、ポインタなどの振る舞いはPythonではあまり表に出てこないが大切な概念である。また、深層学習を行う際はcv::Matへの画像格納方法が通常と異なることに注意しなければならない。Python版のOpenCVであれば画像は全てnumpyのarrayに格納されるので、画像処理と深層学習の間で画像の持ち方に大きな違いはない。後者の場合にバッチサイズ用に次元が1つ増えるだけである。
参考文献
- OpenCV のピクセル形式がBGRである理由
- 【オウム画像の引用元】Webサイト名:神奈川工科大学 情報学部 情報工学科,
URL:http://www.ess.ic.kanagawa-it.ac.jp/app_images_j.html#image_dl - OpenCVではじめよう ディープラーニングによる画像認識