

はじめに
今回はHalideを紹介する。
Halideとは
Halideは、画像処理に特化したDomain Specific Language(DSL)である。高速化を目的とした言語であり、C++プログラム内に記述される。現在対応しているプラットフォームは、x86/SSE, ARM v7/NEON, CUDA, OpenCLである。Halideの大きな特長は、アルゴリズムとスケジューリングの記述を分離する点である。ここでスケジューリングとは
- 並列化
- ベクトル化(SIMD命令の発行)
- ブロック化(処理の局所化)
を組み合わせ、効率よくタスクを実行する手順を見つけることである。ハードウェアに依存しないアルゴリズムの記述が可能であり、各ハードウェアごとに最適なスケジューリングを行うことができる。Halideプログラムの実行までの流れは以下のようになる。
- C++プログラム内にHalideの提供するクラスや関数(Halide::Func, Halide::Expr, Halide::Varなど)を用いてコードを記述する。
- C++コンパイラでオブジェクトファイルを生成する。
- Halideのlibファイル(libHalide.a)とリンクする。Halide::Func, Halide::Expr, Halide::Varなどで書かれた部分は、libHalide.aとリンクすることで実行可能になる。
- 初めてHalideコードが実行されるとき、動的にHalideコンパイラが起動し、高速なバイナリコードが生成され、画像処理が行われる。2回目以降の計算では既存のバイナリコードが使われる。
HalideコンパイラはCで書かれたプログラムであり、libファイル(静的ライブラリ)とヘッダファイルとして提供される。Halideコンパイラは本体プログラムの実行時に動的に起動すると書いたが、静的にHalideコードを実行する(あらかじめHalideコードをコンパイルしておく)手段も提供されている。これについては後述する。
拡大・縮小処理を例に取り、アルゴリズムの説明のあと実際のコードを示す。
拡大・縮小処理のアルゴリズム
拡大・縮小アルゴリズムの手順を以下に示す(下図参照)。
- いま、拡大後のある画素
 を考える。
を考える。 - この画素が元画像ではどこに位置するのかを逆算する。一般的にこの位置座標は浮動小数点で表される(画素
 )。
)。 - 画素の周辺に存在する画素から画素に割り振る画素値を計算する。
 を考える。
を考える。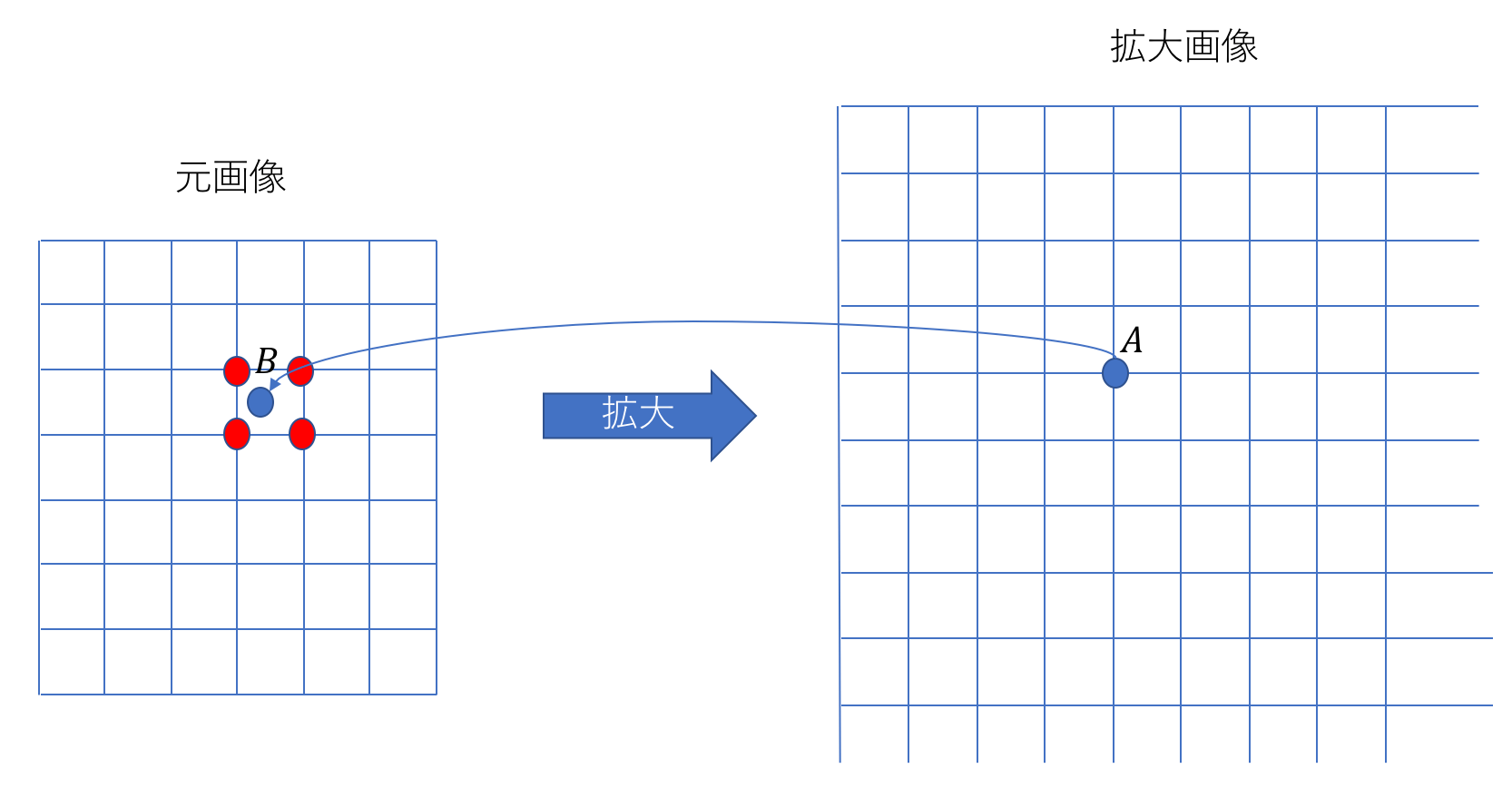
上図において、格子点は画素に相当する。画素 へ割り振る画素値の計算の仕方により以下3つの手法が存在する。
へ割り振る画素値の計算の仕方により以下3つの手法が存在する。
- nearest neighbor法
- bi-linear法
- bi-cubic法
記載した順に処理は重くなり、画質は良くなる。ここでは2番目のbi-linearを取り上げる。
bi-linearでは下図に示した面積 を求める。図中の
を求める。図中の は画素と画素
は画素と画素 の間の水平・垂直方向の距離である。
の間の水平・垂直方向の距離である。
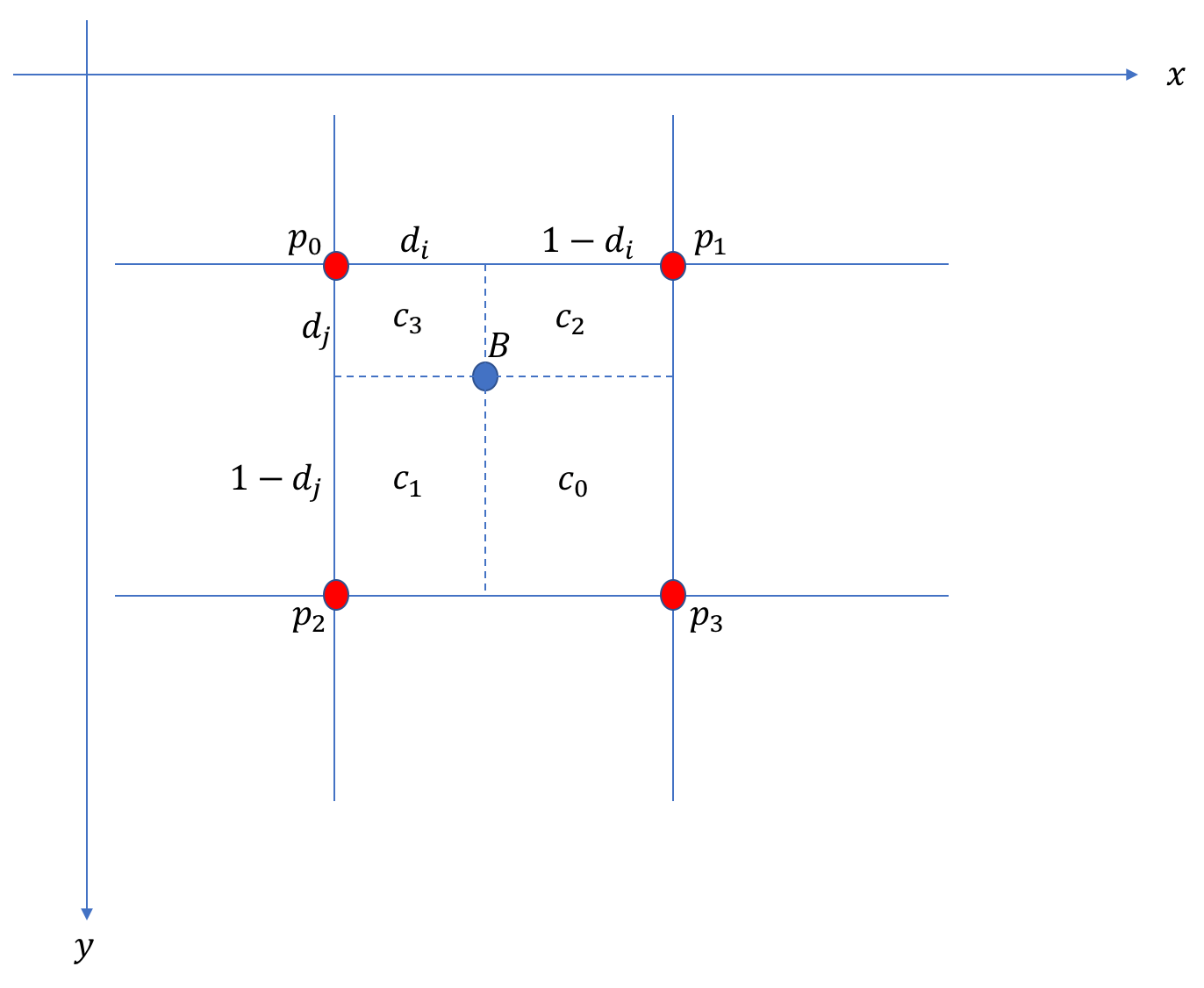
この面積を用いての画素値は次式により計算される。
(1) 
ここで は
は における画素値を表す。グレー画像ならスカラー量、カラー画像なら3次元のベクトル量となる。また、次式が成り立つことに注意する。
における画素値を表す。グレー画像ならスカラー量、カラー画像なら3次元のベクトル量となる。また、次式が成り立つことに注意する。
(2) 
ポインタを用いた実装
あとで比較を行うため、上記のアルゴリズムをHalideを用いず生のポインタを用いて素直に実装する(halide/resize/resize/normal.cpp)。何も特別なことはしていない。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 |
#include "normal.hpp" #include <iostream> #include <opencv2/opencv.hpp> inline const uint8_t* get_pixel(const uint8_t* data, int row, int col, size_t step, size_t elem_size) { return data + (row * step + col * elem_size); } inline uint8_t interpolate(float c0, float c1, float c2, float c3, const uint8_t* p0, const uint8_t* p1, const uint8_t* p2, const uint8_t* p3, int i) { return c0 * p0[i] + c1 * p1[i] + c2 * p2[i] + c3 * p3[i]; } void resize_with_raw_access(const cv::Mat& src_image, cv::Mat& dst_image) { //_/_/_/ 画像の読み込みと保存はOpenCVを使用。 // 入力画像の各種値・ポインタを取り出す。 const int src_cols = src_image.cols; const int src_rows = src_image.rows; const size_t src_step = src_image.step; const size_t src_elem_size = src_image.elemSize(); const uint8_t* src_data = src_image.data; // 出力画像の各種値・ポインタを取り出す。 const int dst_cols = dst_image.cols; const int dst_rows = dst_image.rows; const size_t dst_step = dst_image.step; const size_t dst_elem_size = dst_image.elemSize(); uint8_t* dst_data = dst_image.data; // 拡大縮小率の逆数を計算する。 const float sc = static_cast<float>(src_cols) / dst_cols; const float sr = static_cast<float>(src_rows) / dst_rows; // 拡大縮小後の画素を左上から順に走査する。 // y軸方向の走査 for (auto j = 0, jd = 0; j < dst_rows; ++j, jd += dst_step) { // 元画像における位置yを算出する。 const float fj = j * sr; const int cj0 = static_cast<int>(fj); // 端数を切り捨てる。 const float dj = fj - cj0; // +1した値が画像内に収まるように調整する。 const int cj1 = cj0 + 1 >= src_rows ? cj0 : cj0 + 1; // 拡大縮小後画像へのポインタの位置を更新する。 uint8_t* dst_p = dst_data + jd; // x軸方向の走査 for (auto i = 0, id = 0; i < dst_cols; ++i, id += dst_elem_size) { // 元画像における位置xを算出する。 const float fi = i * sc; const int ci0 = static_cast<int>(fi); const float di = fi - ci0; // dx const int ci1 = ci0 + 1 >= src_cols ? ci0 : ci0 + 1; // 面積を計算する。 const float c0 = (1.0f - dj) * (1.0f - di); const float c1 = (1.0f - dj) * di; const float c2 = dj * (1.0f - di); const float c3 = dj * di; // 周辺画素を取り出す。 const uint8_t* src_pixel0 = get_pixel(src_data, cj0, ci0, src_step, src_elem_size); const uint8_t* src_pixel1 = get_pixel(src_data, cj0, ci1, src_step, src_elem_size); const uint8_t* src_pixel2 = get_pixel(src_data, cj1, ci0, src_step, src_elem_size); const uint8_t* src_pixel3 = get_pixel(src_data, cj1, ci1, src_step, src_elem_size); // ポインタ位置を更新する。 uint8_t* dst_pixel = dst_p + id; // RGB値を計算する。 dst_pixel[0] = interpolate(c0, c1, c2, c3, src_pixel0, src_pixel1, src_pixel2, src_pixel3, 0); dst_pixel[1] = interpolate(c0, c1, c2, c3, src_pixel0, src_pixel1, src_pixel2, src_pixel3, 1); dst_pixel[2] = interpolate(c0, c1, c2, c3, src_pixel0, src_pixel1, src_pixel2, src_pixel3, 2); } } } |
Halideを用いた実装
次に、Halideを用いたコードを示す(halide/resize/resize/halide.cpp)。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 |
#include "halide.hpp" #include <Halide.h> #include <halide_image_io.h> #include <boost/format.hpp> #include <chrono> void resize_with_halide(const std::string& src_path, int dst_cols, int dst_rows, const std::string& dst_path) { // 入力画像を読み込む。 Halide::Buffer<uint8_t> input = Halide::Tools::load_image(src_path); // 画像内に収まるか否かの判定をなくすため、周辺画素を拡張する。 Halide::Func src_image {}; src_image = Halide::BoundaryConditions::repeat_edge(input); //_/_/_/ アルゴリズムを記述する。 const int src_cols = input.width(); const int src_rows = input.height(); const float sc = static_cast<float>(src_cols) / dst_cols; const float sr = static_cast<float>(src_rows) / dst_rows; Halide::Var i {}; Halide::Var j {}; Halide::Var c {}; // 元画像の位置を逆算する。 auto fj = j * sr; // 端数を捨てる。 auto cj0 = Halide::cast<int>(fj); // +1する。 auto cj1 = cj0 + 1; // 距離を計算する。 auto dj = fj - cj0; // 同じことを水平方向についても繰り返す。 auto fi = i * sc; auto ci0 = Halide::cast<int>(fi); auto ci1 = ci0 + 1; auto di = fi - ci0; // 面積を計算する。 const auto c0 = (1.0f - dj) * (1.0f - di); const auto c1 = (1.0f - dj) * di; const auto c2 = dj * (1.0f - di); const auto c3 = dj * di; // 周辺画素を取り出す。 const auto& src_pixel0 = src_image(ci0, cj0, c); const auto& src_pixel1 = src_image(ci1, cj0, c); const auto& src_pixel2 = src_image(ci0, cj1, c); const auto& src_pixel3 = src_image(ci1, cj1, c); // 画素値を計算する。 Halide::Func dst_image {}; dst_image(i, j, c) = Halide::saturating_cast<uint8_t>(c0 * src_pixel0 + c1 * src_pixel1 + c2 * src_pixel2 + c3 * src_pixel3); //_/_/_/ スケジューリングを行う。 Halide::Var i_inner, j_inner; dst_image.tile(i, j, i_inner, j_inner, 64, 4).vectorize(i_inner, 16).parallel(j); //_/_/_/ 実行する。 Halide::Buffer<uint8_t> output {dst_cols, dst_rows, input.channels()}; constexpr auto ITERATIONS = 10; for (auto i = 0; i < ITERATIONS; ++i ) { auto start = std::chrono::system_clock::now(); dst_image.realize(output); auto end = std::chrono::system_clock::now(); std::cout << boost::format("halide access[%1%]: %2% msec\n") % i % std::chrono::duration_cast<std::chrono::milliseconds>(end - start).count(); } //_/_/_/ 保存する。 Halide::Tools::save(output, dst_path); } |
特筆すべき点は、アルゴリズムとスケジューリングの記述が完全に分離していることである。そのおかげでアルゴリズムの理解が大変楽になっていることが分かる。Halideのコンパイラが動的に起動する場所は、74行目のdst_image.realizeである。本サンプルではこれを10回繰り返すが、Halideコンパイラが起動するのは最初の1回目だけである。
最初に示したポインタによる実装は手続き型であるが、Halideを用いた実装は宣言型と呼ぶことができる。ロジックを決定したあと実行するスタイルは、「Define and Run」型のアーキテクチャを採用している深層学習ライブラリ(例えばTensorflow, Theano, Caffeなど)と同じである。
スケジューリング
上記コードに記載したスケジューリング
|
1 2 |
Halide::Var i_inner, j_inner; dst_image.tile(i, j, i_inner, j_inner, 64, 4).vectorize(i_inner, 16).parallel(j); |
は以下を実現する(下図参照)。
- 画像を64
 4のタイルに分割する(処理の局所化)。
4のタイルに分割する(処理の局所化)。 - 水平方向の計算は16画素単位のベクトル化により行う。
- 垂直方向の計算は並列化する。
 4のタイルに分割する(処理の局所化)。
4のタイルに分割する(処理の局所化)。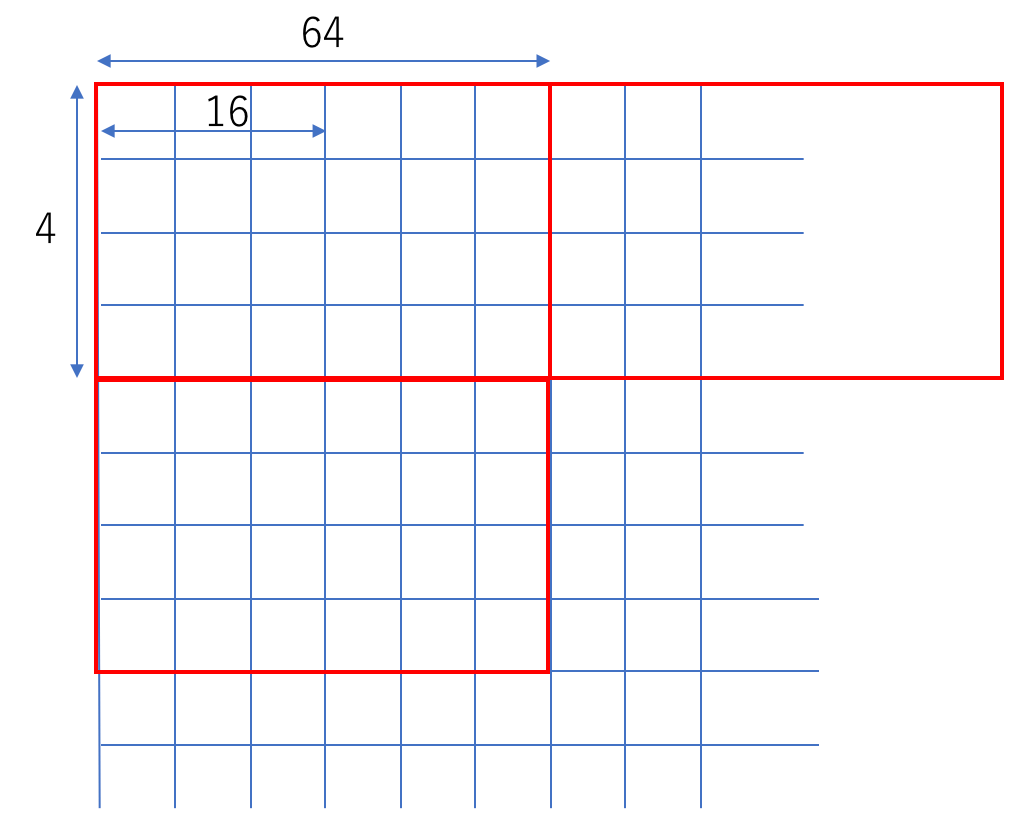
上に示したスケジューリングが最良のものとは限らない。スケジューリングは試行錯誤を伴う作業になる。
速度比較
実行環境
- MacBook Pro (15-inch, Late 2016)
- OS: macOS Sierra
- CPU: 2.9GHz Intel Core i7
- Core数: 4
- Memory: 16GB
- Xcode Version 9.2 (9C40b)
- C++ Language Dialect: C++17[-std=c++17]
結果
下記コマンドで入力画像を拡大する。exeは実行ファイル名、それに渡す最初の引数は入力画像、次の引数は出力先、最後の2つの引数は拡大後の画像サイズである。(src_width,src_height)が元画像のサイズ、(dst_width,dst_height)が拡大後のサイズである。最初の10個が生のポインタの結果、後の10個がHalideの結果である。
[kumada]resize(543)$> ./exe ../images/inputs/src_image_2.jpg ../images/outputs/dst_image.png 4999 3499
(src_width, src_height) = (500, 350)
(dst_width, dst_height) = (4999, 3499)raw access[0]: 279 msec
raw access[1]: 237 msec
raw access[2]: 230 msec
raw access[3]: 236 msec
raw access[4]: 244 msec
raw access[5]: 255 msec
raw access[6]: 239 msec
raw access[7]: 248 msec
raw access[8]: 258 msec
raw access[9]: 242 msechalide access[0]: 505 msec
halide access[1]: 28 msec
halide access[2]: 37 msec
halide access[3]: 33 msec
halide access[4]: 40 msec
halide access[5]: 34 msec
halide access[6]: 44 msec
halide access[7]: 32 msec
halide access[8]: 40 msec
halide access[9]: 39 msec
初回を除けば高速化されていることが分かる。初回の遅さはHalideコンパイラの起動に起因する。これが受け入れられないタスクもあるだろう。これを回避するのが次に示す、処理のライブラリ化である。
処理のライブラリ化
以下のコードにより、Halideコードをコンパイルした後のバイナリを静的ライブラリとして保存することができる(halide/make_halide_static_library_for_resize/make_halide_static_library_for_resize/halide.cpp)。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 |
#include "halide.hpp" #include <Halide.h> void make_halide_static_library_for_resize() { // 入力画像を引数にする。 Halide::ImageParam input {Halide::type_of<uint8_t>(), 3}; // 画像内に収まるか否かの判定をなくすため、周辺画素を拡張する。 Halide::Func src_image {}; src_image = Halide::BoundaryConditions::repeat_edge(input); //_/_/_/ アルゴリズムを記述する。 // 画像サイズを引数にする。 Halide::Param<float> src_rows {}; Halide::Param<float> src_cols {}; Halide::Param<float> dst_rows {}; Halide::Param<float> dst_cols {}; // 拡大・縮小率の逆数を計算する。 const auto sc = src_cols / dst_cols; const auto sr = src_rows / dst_rows; Halide::Var i {}; Halide::Var j {}; Halide::Var c {}; // 元画像の垂直方向の計算 auto fj = j * sr; auto cj0 = Halide::cast<int>(fj); auto cj1 = cj0 + 1; auto dj = fj - cj0; // 元画像の水平方向の計算 auto fi = i * sc; auto ci0 = Halide::cast<int>(fi); auto ci1 = ci0 + 1; auto di = fi - ci0; // 面積を計算する。 const auto c0 = (1.0f - dj) * (1.0f - di); const auto c1 = (1.0f - dj) * di; const auto c2 = dj * (1.0f - di); const auto c3 = dj * di; // 周辺画素を取り出す。 const auto& src_pixel0 = src_image(ci0, cj0, c); const auto& src_pixel1 = src_image(ci1, cj0, c); const auto& src_pixel2 = src_image(ci0, cj1, c); const auto& src_pixel3 = src_image(ci1, cj1, c); // 画素値を計算する。 Halide::Func dst_image {}; dst_image(i, j, c) = Halide::saturating_cast<uint8_t>(c0 * src_pixel0 + c1 * src_pixel1 + c2 * src_pixel2 + c3 * src_pixel3); //_/_/_/ スケジューリングを行う。 Halide::Var i_inner, j_inner; dst_image.tile(i, j, i_inner, j_inner, 64, 4).vectorize(i_inner, 16).parallel(j); //_/_/_/ ライブラリ化する。 const std::string PATH {"/Users/kumada/Projects/cct_blog/halide/resize_using_halide_static_library/resize_using_halide_static_library/resize"}; dst_image.compile_to_static_library( // ライブラリの保存先 PATH, // 引数は以下の5つ。 {input, src_rows, src_cols, dst_rows, dst_cols}, // 関数名はresize "resize"); } |
中身は先に示したコードとほぼ同じである。ただし以下の箇所が異なる。
- 7行目: 入力画像を引数にするためのコードである。
- 16行目から19行目: 入力画像のサイズ、出力画像のサイズを引数にするためのコードである。
- 64行目: ライブラリとヘッダファイルの出力先
- 69行目: 関数の引数は5つ。
- 72行目: 関数名はresize。
出力された静的ライブラリとヘッダファイルを用いた実行コードは以下のようになる(halide/resize_using_halide_static_library/resize_using_halide_static_library/main.cpp)。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 |
int resize_with_halide(const std::string& src_path, int dst_width, int dst_height, const std::string& dst_path) { // 入力画像を読み込む。 Halide::Runtime::Buffer<uint8_t> input = Halide::Tools::load_image(src_path); const int src_cols = input.width(); const int src_rows = input.height(); std::cout << src_cols << ", " << src_rows << std::endl; // 出力画像のバッファを用意する。 Halide::Runtime::Buffer<uint8_t> output {dst_width, dst_height, 3}; std::cout << output.width() << ", " << output.height() << std::endl; constexpr auto ITERATIONS {10}; for (auto i = 0; i < ITERATIONS; ++i) { auto start {std::chrono::system_clock::now()}; // ライブラリが提供する関数resizeを5つの引数を与えて呼び出す。 resize(input, src_rows, src_cols, dst_height, dst_width, output); auto end {std::chrono::system_clock::now()}; std::cout << boost::format("halide access[%1%]: %2% msec\n") % i % std::chrono::duration_cast<std::chrono::milliseconds>(end - start).count(); } Halide::Tools::save(output, dst_path); return 0; } |
- 4行目: 入力画像を読み込む。
- 10行目: 出力画像のバッファを用意する。
- 19行目: ライブラリの提供するresize関数を呼び出す。引数は5つである。
実行結果は以下の通り。
[kumada]resize_using_halide_static_library(555)$> ./exe ../images/inputs/src_image_2.jpg ../images/outputs/dst_image.png 4999 3499
500, 350
4999, 3499
halide access[0]: 55 msec
halide access[1]: 33 msec
halide access[2]: 37 msec
halide access[3]: 30 msec
halide access[4]: 37 msec
halide access[5]: 30 msec
halide access[6]: 38 msec
halide access[7]: 31 msec
halide access[8]: 38 msec
halide access[9]: 32 msec
改善されていることが分かる。この場合の初回の遅さは、キャッシュメモリにオブジェクトが載っているか否かの差であろう。
まとめ
今回は、画像処理に特化したDSLであるHalideを紹介した。アルゴリズムとスケジューリングの記述を切り離した宣言型の言語であることをコード例により示した。スケジューリングは試行錯誤を伴う作業であり、ある程度の慣れが必要である。しかし、SIMD命令を直接呼び出す煩雑さに比べればかなり楽な試行錯誤である。
Halideを使う際に注意しなければならないことは、動的にHalideコンパイルを行うことは、かなり大きなオーバヘッドを伴うということである。静的ライブラリを作ることでこれを回避できることを示した。
Halideは現在も活発に開発が続けられているプロジェクトである。FPGAやスマートフォンなどへも積極的に組み込まれているようだ。これからも注視していきたい。
ソースコード
今回のソースコードはここにある。