

はじめに
先の解説でConditional Variational Autoencoder(CVAE)を取り上げ、画像を生成するモデルを例として考えた。そのとき扱った画像はMNISTデータセットである。このデータセットの画像を2値画像であるとみなし、0と1を生成するベルヌーイ分布を導入した。実は、MNISTの画像は2値画像ではなく、グレイ画像である。今回の記事では、連続値を生成する確率分布(ガウス分布)を用いてグレイ画像をまじめに扱う。本記事では簡単のため、Conditionalではない普通のVariational Autoencoder(VAE)を用いて画像生成モデルを学習する。
ベイズの変分推論
最初にVAEを定式化する。観測値を とし、潜在変数
とし、潜在変数 を考え、これら2つの同時確率分布
を考え、これら2つの同時確率分布 にベイズの定理を適用する。
にベイズの定理を適用する。
(1) 
事後確率 をベイズの変分推論により求める。を近似する関数としてパラメータ
をベイズの変分推論により求める。を近似する関数としてパラメータ を持つ関数
を持つ関数 を導入し、次のKullback-Leibler Divergenceを最小にする。
を導入し、次のKullback-Leibler Divergenceを最小にする。
(2) ![\begin{equation*} D_{KL}\left[q_{\phi}(z|X)||p(z|X)\right] \equiv \int dz\; q_{\phi}(z|X)\ln{\frac{q_{\phi}(z|X)}{p(z|X)}} \end{equation*}](/wp-content/ql-cache/quicklatex.com-f9ab24bef99cef803a0c7e9bb22b967f_l3.png "Rendered by QuickLaTeX.com")
(3) ![\begin{equation*} D_{KL}\left[q_{\phi}(z|X)||p(z|X)\right]= D_{KL}\left[q_{\phi}(z|X)||p(z)\right]-E_{q_{\phi}(z|X)}\left[\ln{p(X|z)}\right]+\ln{p(X)} \end{equation*}](/wp-content/ql-cache/quicklatex.com-1d2d2ee6cb5100b304e9c2cbcd936f58_l3.png "Rendered by QuickLaTeX.com")
となる。ここで、![E_{q_{\phi}(z|X)}\left[\cdot\right]](/wp-content/ql-cache/quicklatex.com-fe508304701d0301753056df11e5da04_l3.png "Rendered by QuickLaTeX.com") はについての期待値を表す。右辺の第3項はに依存しないので、右辺をについて最小にするには次式を最小にすれば良い。
はについての期待値を表す。右辺の第3項はに依存しないので、右辺をについて最小にするには次式を最小にすれば良い。
(4) ![\begin{equation*} L\left[\phi\right]\equiv D_{KL}\bigl[q_{\phi}(z|X)||p(z)\rbig]-\matchbb{E}_{q_{\phi}(z|X)}\left[\ln{p(X|z)}\right] \end{equation*}](/wp-content/ql-cache/quicklatex.com-1267069435bc5ccff562fdb0fb04830f_l3.png "Rendered by QuickLaTeX.com")
ところで、![L\left[\phi\right]](/wp-content/ql-cache/quicklatex.com-3fcb6041fe94dcbbbc6a5be007149d9a_l3.png "Rendered by QuickLaTeX.com") を用いて式(3)を変形すると
を用いて式(3)を変形すると
(5) ![\begin{equation*} \ln{p(X)}=D_{KL}\left[q_{\phi}(z|X)||p(z|X)\right]-L\left[\phi\right] \end{equation*}](/wp-content/ql-cache/quicklatex.com-63c8cf1c06a5b82cff8a9eaa64e5f1cf_l3.png "Rendered by QuickLaTeX.com")
を得る。Kullback-Leibler Divergenceは常に0以上であるから
(6) ![\begin{equation*} \ln{p(X)}\geq -L\left[\phi\right] \end{equation*}](/wp-content/ql-cache/quicklatex.com-946be7f152b6b144f2da65a203f0d2b0_l3.png "Rendered by QuickLaTeX.com")
となる。左辺の量 はEvidenceと呼ばれる量であり、この対数の下限が
はEvidenceと呼ばれる量であり、この対数の下限が![-L\left[\phi\right]](/wp-content/ql-cache/quicklatex.com-65e4ea463b7060e3d5d11b5fc2baca1b_l3.png "Rendered by QuickLaTeX.com") であることを上式は示している。この下限をEvidence Lower Bound(ELBO)と呼ぶ。すなわち、ELBOを最大することと、
であることを上式は示している。この下限をEvidence Lower Bound(ELBO)と呼ぶ。すなわち、ELBOを最大することと、![D_{KL}\left[q_{\phi}(z|X)||p(z|X)\right]](/wp-content/ql-cache/quicklatex.com-66740463cb38b4fec279c7208a91ef2a_l3.png "Rendered by QuickLaTeX.com") を最小にすることとは等価である。いずれにせよ、式(4)を最小するようなを見つけることが目標になる。
を最小にすることとは等価である。いずれにせよ、式(4)を最小するようなを見つけることが目標になる。
深層生成モデル
確率分布を正規分布で表し、そのパラメータである平均 と分散
と分散 をネットワークを用いて計算する。
をネットワークを用いて計算する。
(7) 
ここで、 は
は の関数であり、パラメータはネットワークの各種重みに相当する。ネットワークを用いて表現された生成モデルを深層生成モデルと呼ぶ。本記事ではがグレイ画像の場合を考える。グレイ画像の画素は、0から255までのいずれかの整数値を持つ。従って、
の関数であり、パラメータはネットワークの各種重みに相当する。ネットワークを用いて表現された生成モデルを深層生成モデルと呼ぶ。本記事ではがグレイ画像の場合を考える。グレイ画像の画素は、0から255までのいずれかの整数値を持つ。従って、 として仮定できる確率分布は、255種類の離散値を生成できるものでなければならない。真っ先に思いつくのがカテゴリカル分布である。しかし、実際にこれを用いて計算を行ったところ訓練に大変時間がかかることが分かった。そこで、画素値を255で割り0から1までの実数値に変換した。このようにすれば、任意の実数値を生成できるガウス分布を用いることができる。
として仮定できる確率分布は、255種類の離散値を生成できるものでなければならない。真っ先に思いつくのがカテゴリカル分布である。しかし、実際にこれを用いて計算を行ったところ訓練に大変時間がかかることが分かった。そこで、画素値を255で割り0から1までの実数値に変換した。このようにすれば、任意の実数値を生成できるガウス分布を用いることができる。
(8) 
パラメータ は、入力をとするネットワークで計算される。
は、入力をとするネットワークで計算される。 はネットワークの重みを表す。今回の計算では分散
はネットワークの重みを表す。今回の計算では分散 は定数(ハイパーパラメータ)とした。これもネットワークで決める計算を行ってみたが、損失関数の減衰が不安定であった。最後に、
は定数(ハイパーパラメータ)とした。これもネットワークで決める計算を行ってみたが、損失関数の減衰が不安定であった。最後に、 として次の標準正規分布を仮定した。
として次の標準正規分布を仮定した。
(9) 
ここまでの様子を図にすると以下のようになる。
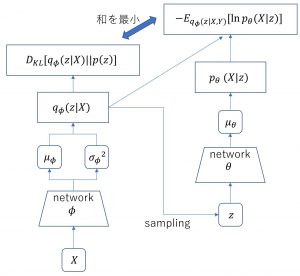
図1. VAEの処理の流れ
結果
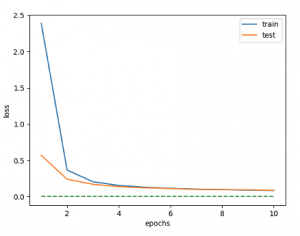
今回もPixyzを用いて実装し、データセットとしてModelNet40を用いた。このデータセットが持つ3Dモデルをさまざまな角度から見た距離画像(グレイ画像)を作成し、これを訓練画像とした。画像枚数はおおよそ9万8千枚である。最初に、訓練時の損失関数の減衰の様子を示す。ハイパーパラメータを0.01とした。
次に、再構成画像を示す。再構成画像とは上の図1で、を入力したときの が生成する画像のことである。この画像がと似てるほどVAEの精度は良い。
が生成する画像のことである。この画像がと似てるほどVAEの精度は良い。

物体の形状と濃淡を完全ではないが再現できていることが分かる。最後に、標準正規分布から発生させた乱数から生成した画像を示す。これは図1の右段だけの処理である。

生成画像については残念な結果になった。何が描画されているのか分からない。もう少し、損失値を減らす工夫が必要そうである。
まとめ
今回は、グレイ画像を生成するVAEを考察した。VAEのサンプルコードをGoogleで検索してもベルヌーイ分布を用いたものしか見つからない。グレイ画像は2値画像ではないからベルヌーイ分布は不適切である。今回の記事では、ガウス分布を導入することでグレイ画像を扱えることを示した。ただし、乱数からの画像生成についてはもう少し丁寧な議論が必要である。