

はじめに
画像処理ライブラリのデファクトスタンダードとなっているOpenCVが、Version3から深層学習をサポートしていることを紹介し、そのサンプルコードを示したい。
深層学習フレームワークの変遷
まず最初に、これまで公開されてきた数々の深層学習フレームワークから主だったもの(私の主観)を取り上げ、それらの歴史的変遷を示す(図1)。
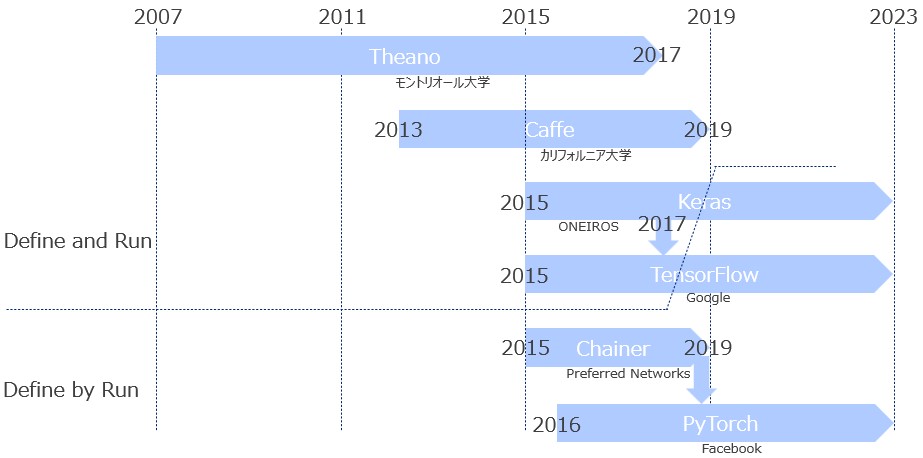
図1
上で挙げたフレームワークの中ではTheano(テアノ)が最も古い(2007年公開)。Theanoは行列やベクトルを用いた計算を効率よく行うために開発されたものであり、さらに自動微分もサポートしていたため、2012年ごろにブレイクした深層学習の実装によく使われた(私も利用した)。そのあと、Caffeが公開される(2013年)。これは設定ファイル(prototxtファイル)にニューラルネットワークの構造をCaffe独自のテキスト形式で記述し、そのファイルを読み込んで計算を行うものであった(煩雑だなと思った記憶が残っている)。2015年、GoogleがTensorFlowを、別のグループがKerasをリリースする。TensorFlowの方は低レベルのAPIを提供し、TensorFlowの低レベルAPIで構成された高レベルAPIをKerasが提供した。私の感想を言えば、TensorFlowはWin32APIに、KerasはMFC(Microsoft Foundation Class)に相当する(この例えが通じる人は年寄りだけかもしれない)。もちろん、後者(KerasやMFC)の方が断然使いやすい。Kerasはバックエンドとして、TensorFlowだけでなくTheanoもサポートしていたが、2017年のTheanoの開発終了とともにそのサポートを止めている。また、同年にKerasはTensorFlowに1モジュールとして吸収された。と思っていたが、2023年11月にKeras3.0がリリースされた。これはTensorFlowのモジュールではないスタンドアロンのKerasである(スタンドアロン版がまだ存在していたことに驚いた)。バックエンドとして、TensorFlow以外にPyTorchとJAXをサポートしている。
図1のTheanoからTensorFlowまでは「Define and Run」と呼ばれるアーキテクチャを採用している。これは、計算の定義(Define)と実行(Run)を分けるアーキテクチャである。以下にTheanoの例を示す。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
import pytensor from pytensor import tensor as at # declare two symbolic floating-point scalars a = at.dscalar() b = at.dscalar() # create a simple expression c = a + b # convert the expression into a callable object that takes `(a, b)` # values as input and computes a value for `c` f = pytensor.function([a, b], c) # bind 1.5 to 'a', 2.5 to 'b', and evaluate 'c' assert 4.0 == f(1.5, 2.5) |
5行目から13行目までが数式の定義(Define)であり、16行目が数式の実行(Run)である。詳細は以下の通り。
- 5行目と6行目で変数
a,bをスカラー量として定義する。 - 9行目で変数
cを計算する数式を定義する。 - 13行目で、[
a,b]を入力としcを出力とする数式をグラフで表現する(図2を参照)。 - 16行目で、実際に値を与えて計算する。
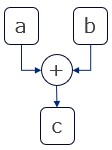
図2
すぐに計算せずグラフで表現することにより以下を実現することができる。
- 実行時間の最適化
- 消費メモリの最適化
一方、欠点は以下の通りである。
- コード量が多くなる。
- デバッグがし難い。
- 動的に計算の構造(ニューラルネットワークの構造)を変更できない。
さて、「Define and Run」とは異なるアーキテクチャ「Define by Run」を採用した深層学習フレームワークも2015年にリリースされる。日本のベンチャー企業Preferred Networksが開発したChainerである。その1年後に同じアーキテクチャを採用したPyTorchがFacebookから公開された。これはChainerのコードの一部をフォークして開発が始まったフレームワークであったが、ユーザ数が急激に伸びていき、2019年にPreferred Networksが自社の開発をPyTorchで行う旨を発表し、Chainerはその使命を終えた。「Define by Run」は通常の手続き型プログラミングと同じ書き方で実装できるため、「Define and Run」で挙げた欠点がない。また、昨今のGPUの発展やPCの高性能化により、実行時間や消費メモリが問題になることはなくなりつつある。そのため、TensorFlowも2018年ごろを境に「Define by Run」に移行している。現在はPyTorchとTensorFlowの2強時代である(JAX/Flaxのような新興勢力も出てきているけれど)。
OpenCVとは
次に、OpenCVの歴史的経緯を示す。
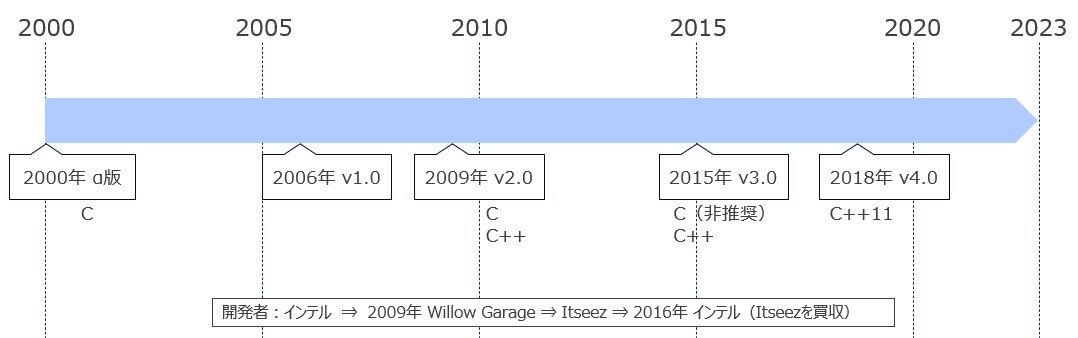
図3
OpenCVはインテルにより開発された画像処理ライブラリであり2000年にα版が公開された。CVとはComputer Visionのことであり、CVに関わる様々なアルゴリズムが実装されている。リリース当初からクロスプラットフォームを意識した設計がなされており現在では以下のプラットフォームをサポートしている。
- Windows
- Linux
- macOS
- iOS
- Android
- FreeBSD
- OpenBSD
公開当時はC言語で実装されていたが、Version2でC++が加わり、Version3以降ではCが非推奨となった。現在ではCは廃止されC++11で実装されている。また、以下の言語のバインディングを提供している。
- Python
- Objective-C/Swift
- Java
- Javascript
- MATLAB
開発元も二転三転したが、結局、インテルに落ち着いているようだ。
OpenCVによる深層学習
深層学習はCV分野でも広く使われる技術なので、OpenCVはVersion3から深層学習をサポートしている。他の深層学習フレームワークが学習と推論の両方をサポートする中、OpenCVは推論機能だけを提供する。「さまざまな深層学習フレームワークで学習されたモデルを読み込み、OpenCVの統一的なインターフェースを用いて推論する」ことを目標としているようだ。対応している深層学習フレームワークは以下の通り。
- Caffe
- Darknet(C言語実装された深層学習フレームワーク)
- OpenVINO
- ONNX(オニキスと読む)
- TensorFlow
- Torch7
CaffeやTensorFlowはこの記事の最初に紹介したが、それ以外は正直なところマニアックである(主観)。ONNXは複数のフレームワークが作成したモデルを共通化するためのフォーマットである。OpenVINOはインテルが出している推論を最適化するエンジンらしい(インテルはOpenCVの開発元)。残念ながら、PyTorchはサポートされない(なぜ?)のでONNX形式のモデルに変換する必要がある。
次に示す表は、OpenCVの深層学習がサポートするターゲットデバイスの種類とバックエンド実装の種類である。
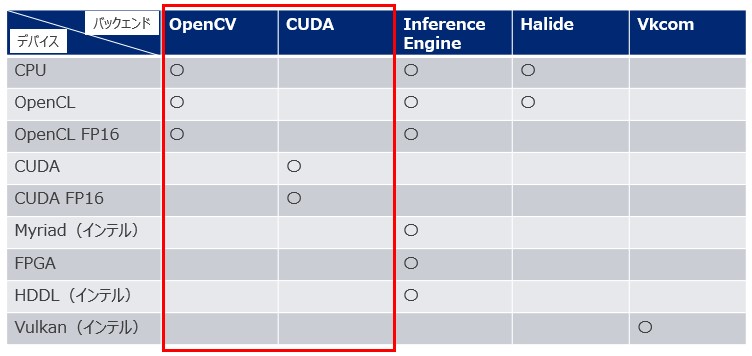
図4
バックエンドとしてOpenCVを選択するとOpenCVが独自に実装している推論エンジンが使われ、バックエンドとしてCUDAを選択するとcuDNN(NVIDIAのライブラリ)を用いて実装された推論エンジンが使われる。デバイスの項に並ぶMyriad、HDDL、Vulkanはどれもインテルが出しているハードウェア-あるいはアクセラレーターである。詳細は割愛する。
プログラムの構造
OpenCVの深層学習モジュールを使う場合、深層学習の種類に関わらずプログラムの構造はほぼ以下の流れに従うようだ。
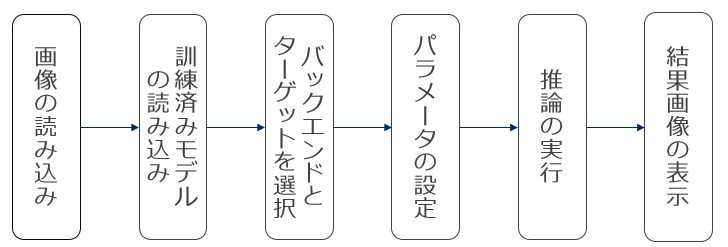
図5
サンプルコード(顔認識)
ソースコード(C++)は、こちらのファイルの関数opencv_face_detectorである。以下では主要部分だけを示す。
画像の読み込み
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
// パスの有無を確認する。 const auto FILE_PATH = std::string{"c:/data/opencv_book/physics_color.jpg"}; if (!fs::exists(FILE_PATH)) { std::cout << "invalid file path\n"; return; } // 画像を読み込む。 auto image = cv::imread(FILE_PATH, cv::IMREAD_COLOR); if (image.empty()) { std::cout << "invalid file\n"; return; } |
- 名前空間
cvの修飾が付いた関数がOpenCVのAPIである。 - 9行目:
cv::imreadで画像を読み込む。
訓練済みモデルの読み込み
|
1 2 3 4 |
// 予測モデルを読み込む。 const auto weights_path = std::string{"c:/data/opencv_book/7.2/7.2/opencv_face_detector/opencv_face_detector_fp16.caffemodel"}; const auto config_path = std::string{ "c:/data/opencv_book/7.2/7.2/opencv_face_detector/opencv_face_detector_fp16.prototxt" }; auto model = cv::dnn::DetectionModel{ weights_path, config_path }; |
- 2行目:Caffeで作成した訓練済みモデルへのパス
- 3行目:Caffeで使用するprototxtファイルへのパス
- 4行目:これら2つのファイルをクラス
cv::dnn::DetectionModelのコンストラクタに渡し顔検出器を構築する。dnnはOpenCVの深層学習をまとめたモジュール名である。
バックエンドとターゲットを選択
|
1 2 3 |
// バックエンドとデバイスを設定する。 model.setPreferableBackend(cv::dnn::DNN_BACKEND_OPENCV); model.setPreferableTarget(cv::dnn::DNN_TARGET_CPU); |
- 2行目:バックエンドはOpenCV独自の実装を選択
- 3行目:ターゲットデバイスはローカルPCのCPUを選択
パラメータの設定
|
1 2 3 4 5 6 7 8 |
const auto scale = 1.0; // スケールファクター const auto size = cv::Size(1600, 806); // 入力サイズ const auto mean = cv::Scalar(104.0, 177.0, 123.0); // 差し引かれる平均値 const auto swap = false; // BGR, true -> RGB const auto crop = false; // モデルのパラメータを決める。 model.setInputParams(scale, size, mean, swap, crop); |
- 1行目:画素値は0~255までの値をそのまま使う。
- 2行目:ニューラルネットワークへの入力画像のサイズは
 である。
である。 - 3行目:入力画像の各画素から差し引かれる画素値である。
- 4行目:入力画像の画素値はBGRの順に並んでいる(OpenCVはなぜかRGBの順に並んでいない)。
- 5行目:入力画像のクロップはしない(中央を切り抜くことはしない)。
- 8行目:モデルにこれらパラメータを設定する。
 である。
である。推論の実行
|
1 2 3 4 5 6 7 |
// 顔を検出する。 auto classIds = std::vector<int>{}; auto confidences = std::vector<float>{}; auto boxes = std::vector<cv::Rect>{}; auto confidence_threshold = 0.6f; auto nms_threshold = 0.4f; model.detect(image, classIds, confidences, boxes, confidence_threshold, nms_threshold); |
- 2行目から4行目:出力値の準備
- 5行目:信頼度の設定(この値より大きい顔だけを残す)
- 6行目:重複するバウンディングボックスのIoUがこの値を越えるとき2つのバウンディングボックスを統合する。
- 7行目:顔を検出する。
結果画像の表示
|
1 2 3 4 5 6 7 |
// 顔を囲む。 for (const auto& box : boxes) { cv::rectangle(image, box, cv::Scalar(0, 0, 255), 1, cv::LINE_AA); } cv::imshow("face detection", image); cv::waitKey(0); |
- 3行目:顔を赤線で囲む。
- 6行目:結果画像を表示する。
得られた結果は以下の通り。

図6
上の画像は、1927年に開催された第5回ソルベー会議において撮影された集合写真である(こちらから引用した)。現代の物理学を創り上げた錚錚たる顔ぶれが並んでいる。その顔を全て認識できている(笑)。
まとめ
今回は、OpenCVが提供する深層学習モジュールを紹介した。世の中の深層学習フレームワークはほとんどがPythonのAPIで提供される。C++で深層学習の推論ができる部分がOpenCVの強みかもしれない。
参考文献
- OpenCVではじめよう ディープラーニングによる画像認識
- OpenCV Wikipedia
- 【集合写真の引用元】Webサイト名:Rare Historical Photos、URL:https://rarehistoricalphotos.com/solvay-conference-probably-intelligent-picture-ever-taken-1927/