

はじめに
今回はNeRFと呼ばれる手法を紹介する。これは、複数枚の画像から任意視点の画像を生成するアルゴリズムである。さらに、本手法の中で学習される「輝度場(Radiance Field)」を利用し点群生成を試みる。
NeRFとは
NeRFと言う単語はNeural Radiance Fieldの略語であり、日本語に訳すと「ニューラル輝度場」である。NeRFは以下の2点を実行する。
2020年に本手法が発表されると多くの研究者に注目され、その派生研究が広く行われるようになった。ここではアルゴリズムの概略を説明する。
概略
本手法で扱う場は、座標( )を指定すれば、その場所における1つのベクトル
)を指定すれば、その場所における1つのベクトル が定まるような空間内の物理量のことである(下図左)。これは物理学に現れるベクトル場に相当する。
が定まるような空間内の物理量のことである(下図左)。これは物理学に現れるベクトル場に相当する。
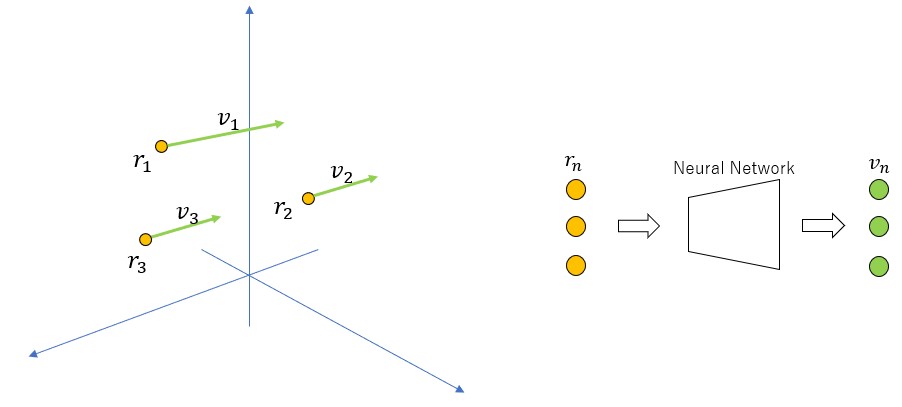
NeRFでは上の右図のように、空間座標を入力するとその点におけるベクトルを出力するようなネットワークを学習する。ベクトルは、色 と密度(
と密度( )から構成される4次元ベクトルである。下図(元論文から引用)は、NeRFが任意視点の画像を生み出すまでの大まかな手順である。
)から構成される4次元ベクトルである。下図(元論文から引用)は、NeRFが任意視点の画像を生み出すまでの大まかな手順である。
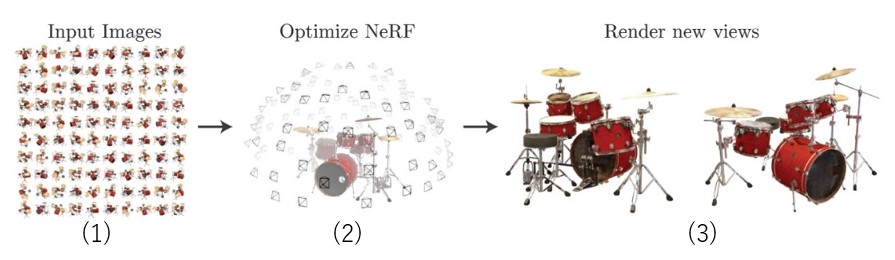
- 複数枚の画像を用意する。画像にはカメラの内部パラメータ(焦点距離)と画像ごとに異なる外部パラメータ(変換行列)も付随している。
- これらの画像とカメラパラメータを用いて輝度場を学習する。空間内の各点における色
 と密度(
と密度( )を予測できるようになる。
)を予測できるようになる。 - ボリュームレンダリングを行うことにより任意の視点から見た画像を生成する。
こちらのページで論文著者らのデモを見ることができる。
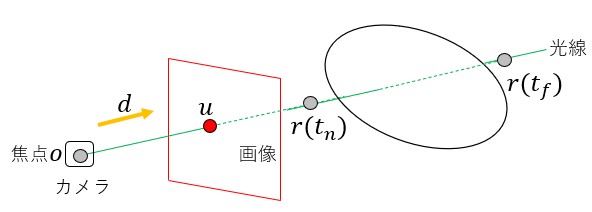
ここからは、さらに詳細な説明を行う。下図は画像と物体の関係を示したものである。
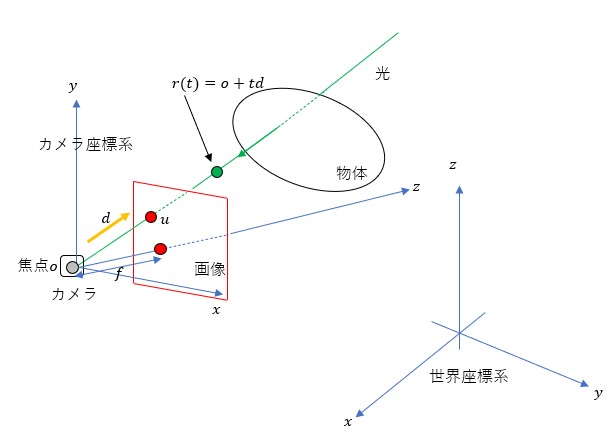
空間内にはカメラ座標系と世界座標系が存在する。前者はカメラごとに(視点ごとに)変化する座標系であり、後者は全カメラに共通する絶対座標系である。この2つの座標系はカメラの内部パラメータ(焦点距離)と外部パラメータ(変換行列)を用いて行き来できる。焦点 から
から 軸正の方向に焦点距離
軸正の方向に焦点距離 だけ離れた場所に、
だけ離れた場所に、 平面に平行な平面(画像となる平面)が置かれる(図の赤枠)。これを画像平面と呼ぶことにする。赤丸は画像平面上の点である。物体後方から焦点に向かう光線(緑線)と画像平面との交点
平面に平行な平面(画像となる平面)が置かれる(図の赤枠)。これを画像平面と呼ぶことにする。赤丸は画像平面上の点である。物体後方から焦点に向かう光線(緑線)と画像平面との交点 が画像の一部をなす色を与える。また、焦点から緑線方向の単位ベクトル(黄色線)を
が画像の一部をなす色を与える。また、焦点から緑線方向の単位ベクトル(黄色線)を とおくと緑線上の座標
とおくと緑線上の座標 は
は と書くことができる。ここで
と書くことができる。ここで は緑線上で定義される0以上の実数である。
は緑線上で定義される0以上の実数である。 のとき
のとき となる。先の説明で輝度場の入力を位置座標としたが正確に言うと、単位ベクトルも入力として加わる(下図参照)。
となる。先の説明で輝度場の入力を位置座標としたが正確に言うと、単位ベクトルも入力として加わる(下図参照)。
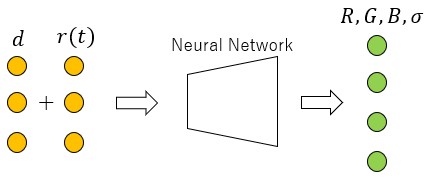
上図の輝度場を複数枚の画像を用いて学習するには、輝度場が画像を作り出すメカニズムを理解する必要がある。ここで使われるロジックはボリュームレンダリングである(下図参照)。
画像上の点における色 は光線上の色を積分したものである。
は光線上の色を積分したものである。
(1) 
積分範囲は図のように から
から までの範囲である。この範囲はあらかじめ決めておく。
までの範囲である。この範囲はあらかじめ決めておく。 (色)と(密度)は輝度場が出力する値であり、
(色)と(密度)は輝度場が出力する値であり、 は次式で計算される量である。
は次式で計算される量である。
(2) 
ここで、式(2)の意味を考えてみる。
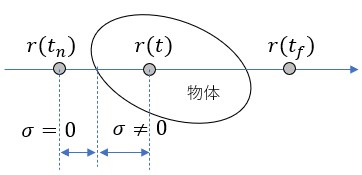
上図において物体の存在しない部分では であり、物体の存在する部分では
であり、物体の存在する部分では となる。位置
となる。位置 が物体の内部に入れば入るほど、
が物体の内部に入れば入るほど、 の値は小さくなる。これは、式(1)に戻って考えると、位置における色の寄与が小さくなることを意味している。
の値は小さくなる。これは、式(1)に戻って考えると、位置における色の寄与が小さくなることを意味している。
式(1)を用いれば画像を構成することができるので、予測した画像が実際の画像と近くなるにように学習させることができる。NeRFではきれいな画像を実現するためさらに工夫が施されているが、その内容については割愛する。興味があれば元論文を見てほしい。
実験
論文著者らのコードはここにあるが、今回は別の人が実装したこちらのコードを利用した(大変分かりやすいコードである)。私が実際に計算したコードはこちらに置いた。実験に使用したデータセットはこちらの「synthetic_scenes.zip」である。このデータセットに含まれる「shoe」データを使用した(下図はサンプル画像)。これらはCG画像である。

データセットには、カメラの内部パラメータ(焦点距離)と、画像ごとに異なるカメラの外部パラメータ(変換行列)が付属する。画像枚数は479枚である。学習のあと視点を軸周りに回転させ、学習時に存在しない視点の画像を生成させることができた(下図参照)。

点群生成
上の実験結果を見る限り、輝度場は上手く学習されているようである。ここから先は私の思い付きだ。輝度場は任意の座標における色と密度を生成できるので、空間を細かいグリッドに分割したくさんの格子点を発生させ、各格子点における色と密度を算出すれば点群が作れるのではないか。密度がある値以上になる点だけを拾うと次の結果を得た。
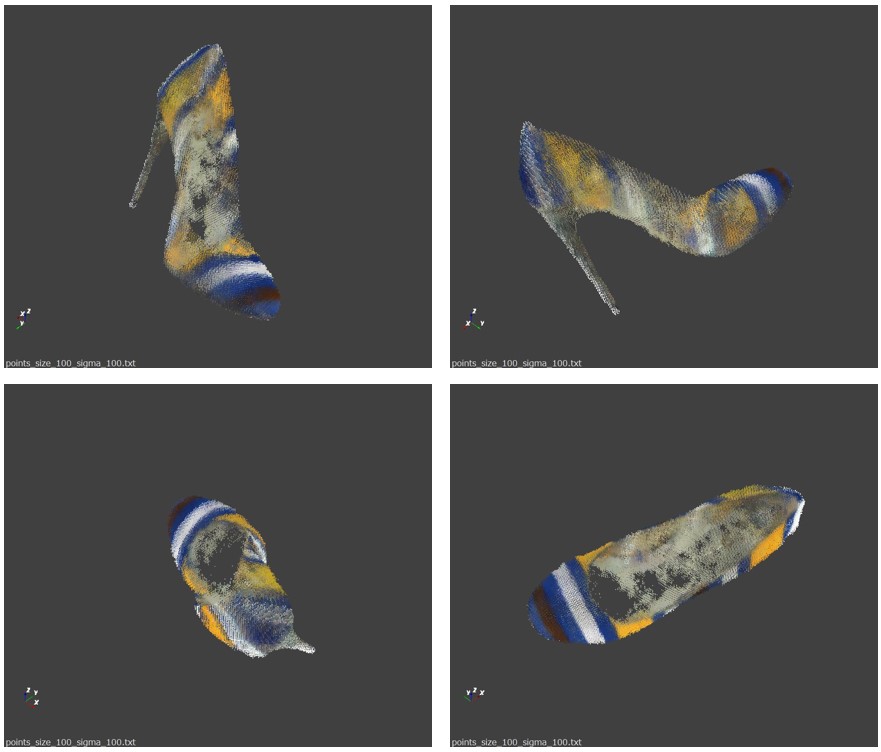
見事に点群(色付き)ができている。つまり、画像とカメラパラメータから点群を生成できたことになる。
まとめ
今回は今流行りのNeRFの元論文を紹介し、それを用いて点群生成を試みた。詳細な考察はこれからである。今後やりたいことは以下である。