

はじめに
深層学習フレームワークの主流は、TensorFlowとPyTorchの2択に収束しつつある。前者はGoogleが、後者はFacebookが開発したオープンソースである。ところが最近、JAXと呼ばれる新興ライブラリがじわじわと勢力を広げてきた。開発元はTensorFlowと同じGoogleである。Googleは、たとえ社内のパイを食い合うことになろうと、次々と新しいものを作る社風だ。今回は、このJAXを取り上げる(先日、PyTorchもJAXに触発されてJAXライクなライブラリfunctorchをリリースした)。
JAXとは
JAXの特徴は以下の通り。
JAXは深層学習に特化したライブラリではなく、その基盤となるライブラリである。すでにJAXを利用した深層学習や深層強化学習のフレームワークが作られている。
問題設定
具体的な問題を与え、老舗のフレームワークPyTorchとの速度比較を行う。対象とする問題は簡単な単回帰である。
観測データ が与えられたとき、
が与えられたとき、 と
と の間の関係を次の形で求めたい。
の間の関係を次の形で求めたい。
(1) 
(2) 
この関数の値を最小にするようなパラメータ を、勾配降下法により求める。各パラメータの更新式は次の通りである。
を、勾配降下法により求める。各パラメータの更新式は次の通りである。
(3) 
ここで、 は学習率と呼ばれる正の微小量である。損失関数の変動がなくなるまで上の更新を繰り返す。
は学習率と呼ばれる正の微小量である。損失関数の変動がなくなるまで上の更新を繰り返す。
ここからは具体的な実装例をコードを抜粋して示す。全ソースはここにある。
観測データの作成
以下のコードで観測データを作成した。
|
1 2 3 4 5 6 |
# PyTorch版 def create_dataset(a, b, n, seed): np.random.seed(seed) x = np.random.rand(N) y = a * x + b + 0.5 * np.random.randn(n) return torch.tensor(x), torch.tensor(y) |
|
1 2 3 4 5 6 |
# JAX版 def create_dataset(a, b, n, seed): np.random.seed(seed) x = np.random.rand(N) y = a * x + b + 0.5 * np.random.randn(n) return jnp.array(x), jnp.array(y) |
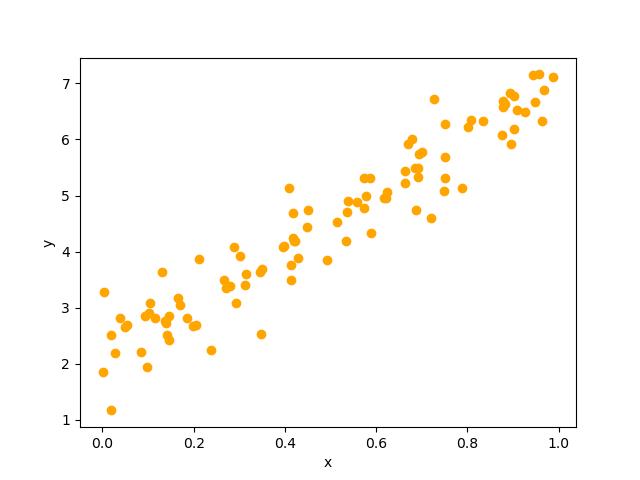
jnpはjax.numpyの別名である。PyTorch版、JAX版のどちらの関数もNumPyでデータを作成し、最後にそれぞれのライブラリで使えるインスタンスに変換している(6行目)。今回は、 とし、そこにノイズを追加してある(下図参照)。
とし、そこにノイズを追加してある(下図参照)。
学習コード:PyTorchの場合
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
# initialize params a = torch.tensor([1.0], requires_grad=True) b = torch.tensor([0.0], requires_grad=True) epochs = 10000 start = time.time() for i in range(epochs): zero_grad(a, b) y_pred = model(x, a, b) loss_value = loss(y_pred, y) loss_value.backward() update(a, b, lr=1e-2) end = time.time() print(f"{end - start}[sec]") |
一般的なPyTorchの学習手順である。
 と
と のそれぞれを0に初期化する。
のそれぞれを0に初期化する。y_predである。とが計算される。
lrは学習率である。学習コード:JAXの場合
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
# set hyperparameters epochs = 10000 lr = 1.0e-2 # train if len(args) == 2 and args[1] == "fori": # run using fori! start = time.time() params = train(epochs, x, y, lr, params) end = time.time() else: start = time.time() for _ in range(epochs): params = train_(x, y, params) end = time.time() |
JAX版に対しては以下2つの場合の速度比較を行った。
jax.lax.fori_loopを使う方法(9行目)
先に後者の説明を行う。ここで呼び出している関数train_の中身は以下の通り。
|
1 2 3 4 5 6 7 |
@jax.jit def train_(x, y, params): # d(loss)/dx grads = grad_loss(params, x, y) # update "params" params = update(params, grads, lr) return params |
jax.jitを付けるとJITコンパイルされる。とを計算する。
4行目のgrad_lossの正体は以下の通り。
|
1 2 3 4 5 6 |
def loss(params, x, y): y_pred = model(params, x) return jnp.power(y_pred - y, 2).mean() # differentiate "loss" with respect to its first argument grad_loss = jax.grad(loss, argnums=[0]) |
関数lossは式(2)を実装したものである。この関数をjax.gradに渡し、params(lossの第1引数)で微分させている(6行目)。paramsの中身は以下の通り。
|
1 2 |
# initialize params params = {"a": jnp.array(1.0), "b": jnp.array(0.0)} |
つまり、で が微分される。
が微分される。
次に、学習ループを包含する関数jax.lax.fori_loopを使う方法を解説する。以下の9行目である(再掲)。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
# set hyperparameters epochs = 10000 lr = 1.0e-2 # train if len(args) == 2 and args[1] == "fori": # run using fori! start = time.time() params = train(epochs, x, y, lr, params) end = time.time() else: start = time.time() for _ in range(epochs): params = train_(x, y, params) end = time.time() |
関数trainの中身は以下の通り。
|
1 2 3 4 5 6 7 8 9 10 11 |
@jax.jit def train(epochs, x, y, lr, params): def body_fun(idx, params): # d(loss)/dx grads = grad_loss(params, x, y) # update params params = update(params, grads, lr) return params params = jax.lax.fori_loop(0, epochs, body_fun, params) return params |
関数内関数body_funを定義している。これは先に見たtrain_の中身と同じである。関数body_funは、10行目のjax.lax.fori_loopに渡される。実はこの関数は次のコードと同じ意味を持つ。
|
1 2 3 4 |
val = params for i in range(0, epochs): val = body_fun(i, params) return val |
詳細なからくりは調べていないが、ループをjax.lax.fori_loopに置き換えると大変顕著に高速化されることを次に示す。
速度比較
実行環境はAWS EC2インスタンス p3.2xlargeである。そのスペックは以下の通り。
学習時間の一覧は以下の通り。
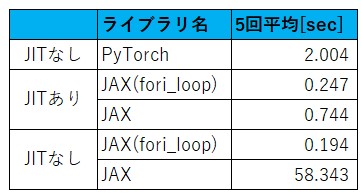
PyTorchとJAXのいずれに対してもGPUを有効にしてある。PyTorchでもJITを使うことができるらしいが、今回は割愛した(コードを全面的に書き直す必要があるようだ)。上の結果を見ると、最速は、JITなしのJAX(fori_loop)版であることが分かる。これは少し意外である。素直に考えれば、JITありのJAX(fori_loop)版になりそうだからだ。おそらく、今回の計算処理は軽いので、動的コンパイルのためのオーバヘッドの方が大きかったのだろう。JITコンパイルの有無に関わらずjax.lax.fori_loopは積極的に使うべきである。
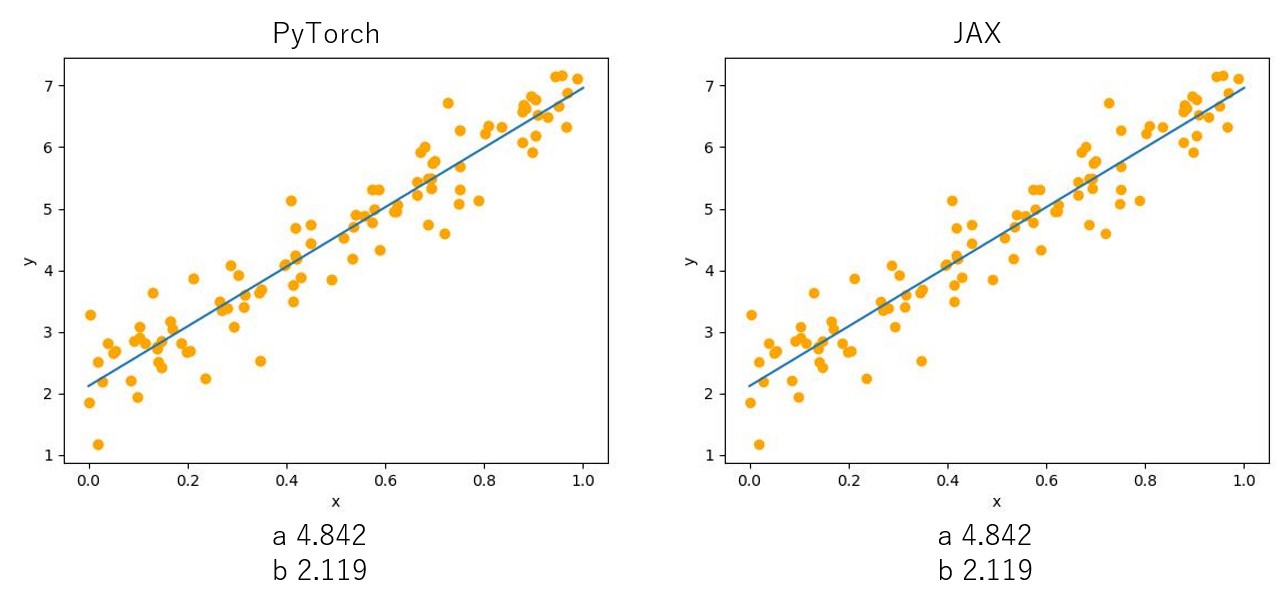
最後に、予測された直線との値(小数点以下4位で四捨五入した)を示す(下図参照)。正解値はである。
参考文献
まとめ
今回は、最近流行のJAXを取り上げ、PyTorchとの速度比較を行った。JAXは確かに速いことが分かった。JAXのJITコンパイルに使われるコンパイラーはGoogleが開発したものでありXLAと呼ばれる。気になる方は調べてほしい。また、JITコンパイルの有無に関わらず、ループを特定の関数で置き換えると大変高速になることも示した。
ところで、JAXは何の略なのか。「What does JAX stand for?」でググったが良く分からなかった。jax.lax.fori_loopのforiの由来も分からない。