

みなさん、SQL書いてますか?
O/Rマッパを使っていると、なかなかSQLを書く機会というものが巡ってきません。
今回、SQLのパフォーマンスチューニングをする機会が来ましたので、対応内容と観点についてまとめます。
今回のRDBは、SQL Server2017 です。
ちなみに、このRDBはパッケージソフトの裏にいるRDBであり、以下の縛りがあります。
- パッケージ上の機能からテーブルのCreate/Alterがガシガシ実行されます
- なので、SSMS上から直接スキーマを変更したりすることは怖くてできません。
- Create Indexくらいは良いのではないか?
- 誰も「作ってもいいよ」と保証してくれるわけではないので却下
- 自分で書いたSQLを実行してくれる仕組みはパッケージ上の機能としてあります
- 今回のチューニングは、その「自分で書いたSQL」を対象としています
今回は、「インデックスに頼らない」という縛りを入れた上でのパフォーマンスチューニングになります。
やったこと
- 再現させる
- 計測する
- 実行計画を見る
- 修正する
- 検証する
再現させる
業務上許容しなければならないデータ量のクエリが、結果が返ってくるまで約3分かかっていました。
どのクエリが遅いか、というのは特定できています。
まずは、再現させましょう。
バックアップを取得して、ローカルに復元。
該当クエリを実行してみたところ、3分10秒で返ってきました。ローカルにて事象を再現できました。
計測する
もう少し細かい単位で計測してみます。
このクエリ、サブクエリ1~3で必要なデータを集めてきて、サブクエリ4~10でトランザクションテーブルから情報を付与しています。
そこで、サブクエリごとの処理時間と件数を取ってみます。
| サブクエリ | 処理時間(秒) | 件数 |
| サブクエリ1 | 0 | 286 |
| サブクエリ2 | 1 | 8996 |
| サブクエリ3 | 5 | 29490 |
| サブクエリ4 | 6 | 29490 |
| サブクエリ5 | 6 | 29490 |
| サブクエリ6 | 6 | 29490 |
| サブクエリ7 | 6 | 29490 |
| サブクエリ8 | 188 | 29490 |
| サブクエリ9 | 189 | 29490 |
| サブクエリ10 | 190 | 29490 |
| 最終結果 | 198 | 18678 |
サブクエリ8の部分で突然時間がかかるようになったことがわかりました。
実行計画を見る
サブクエリ8に手を打てばよさそうに思いますが、手を付ける前に、裏を取りましょう。
推定実行プランを取ります。
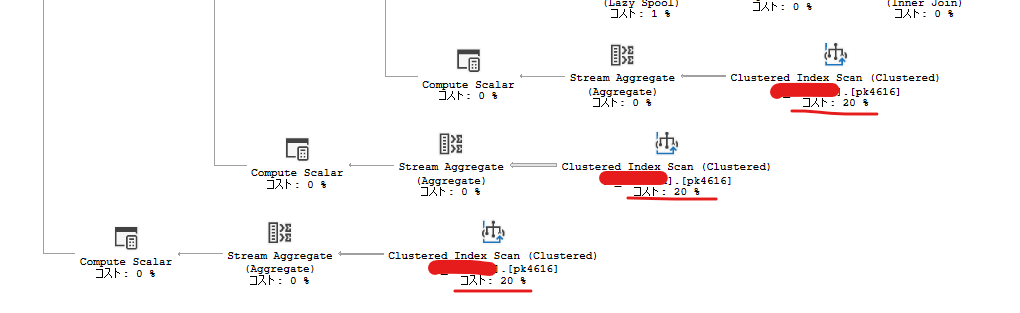
サブクエリ8は同じテーブルを3回参照しているのですが、それぞれ実行コストが20%。
サブクエリ8が実行コストの60%を占めていると言っています。
これで裏が取れました。
実行コストが20%かかっているSQLは以下の通りです。(実際のSQLをブログ用に一部改変しています)
|
1 2 3 4 5 6 7 8 9 |
SELECT SOURCE_ID, MAX(SYMBOL) AS SYMBOL, THEME_ID, MAX(DATA_TYPE) AS DATA_TYPE FROM DATA1 WHERE DATA_TYPE = '1' GROUP BY SOURCE_ID, THEME_ID |
修正する
意外と忘れがちなのですが、目標の時間を決めます。
「できる限り速くする」はもちろんなのですが、限度はあるので。最低限の妥協できるラインを決めた上で対応となります。
今回は、業務上の最大件数であることから、15秒が妥協できるラインでした。
いざ修正
実行コストが20%になっている箇所がどうにからならないか、ということで、テーブルのスキーマを確認しつつ、SQLを読み返してみます。
THEME_ID
あ、このカラム、入力の引数から導出できるやん、と気づきました。
親子テーブルの、子のキーを列挙した文字列が入力の引数なので、親テーブルのキーを導出ができます。
パッケージの仕様上入力の引数に配列を渡せないので、やむなくカンマ区切りの文字列を渡して、クエリ内でsplitしています。
DECLARE ステートメントを追加して、親テーブルのキー(theme_id)を導出します。
これがもともとの入力の引数で渡ってくる値。
|
1 |
DECLARE @ids NVARCHAR(MAX) = 'hoge,fuga,piyo'; |
親テーブルのキー(@theme_id)を導出します。
|
1 2 3 |
DECLARE @ids NVARCHAR(MAX) = 'hoge,fuga,piyo'; DECLARE @topid NVARCHAR(32) = (SELECT TOP 1 * FROM STRING_SPLIT(@ids, ',')); DECLARE @theme_id NVARCHAR(32) = (SELECT TOP 1 THEME_ID FROM T_xxxxxx WHERE xxxx_ID = @topid); |
これで、クエリ内のWHERE句に親テーブルのキーを指定できるようになりました。
指定しましょう。
|
1 2 3 4 5 6 7 8 |
SELECT SOURCE_ID, MAX(SYMBOL) AS SYMBOL FROM DATA1 WHERE DATA_TYPE = '1' AND THEME_ID = @theme_id GROUP BY SOURCE_ID |
THEME_IDをWHERE句で指定した結果、SELECT句からもGROUP BY句からの不要になりました。
また、DATA_TYPEのMAXを取っていましたが、元々WHERE句に指定してあったので1しか返ってきません。使わないので外しました。
サブクエリ8だけでなく、親テーブルのキーで先に絞り込める箇所(サブクエリ6,9,10)にも絞り込みを入れて、実行。
12秒。
ひとまず妥協ライン突破。
検証する
妥協ラインは突破したところで、ここで一旦検証します。
検証のポイントは、処理速度・件数に加えて、クエリが返す結果セットが変更前後で変わっていないか、です。
今回は20,000件もいかないので、変更前・変更後をそれぞれExcelのシートにエクスポートし、変更前・変更後のシートの同じセルアドレスを比較する方法を採用しました。
※ クエリでOrder Byを指定してない場合は、追加してソート順を合わせないと不一致になりますので要注意。
次回へ続く
今回は、絞り込み条件を追加するだけの修正になりましたが、もう一つ手を入れて、4秒まで持って行ったのですが、それは次回に。
次回、もう一つ手を入れた箇所についての解説をします。
※ その時に、クエリが返す結果セットが変更前後で変わっていないか、の検証を端折ったために問題が発生したのですが。。。
読んでいただき、ありがとうございました。
おまけ
推定実行プランを取った時に、SSMSが「不足しているインデックス」を教えてくれていました。
「インデックスに頼らない」という縛りがあったわけですが、縛りを外して、SSMSが教えてくれたことを素直にやってみたらどうなるのか、も検証しておきましょう。
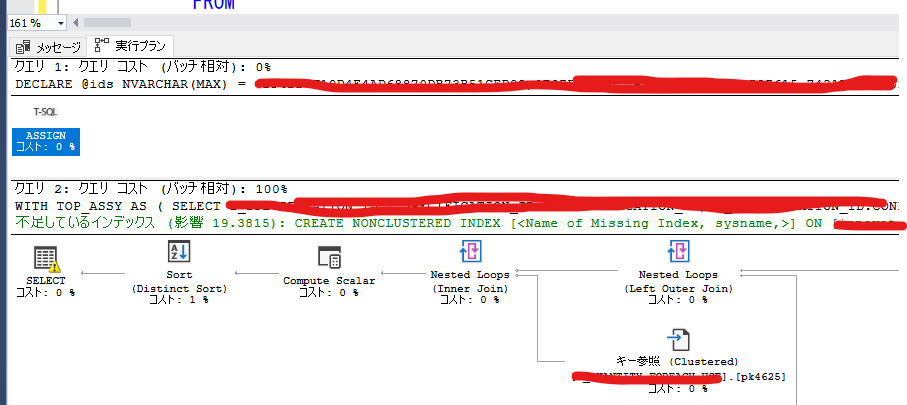
このインデックスをSSMSから適用して、再実行。
4秒。
15秒の妥協ラインも突破。完了でした。
SSMSが教えてくれる「不足しているインデックス」は効果絶大ですね。