

概要
以前の記事「MCP Python SDKによるMCPサーバの構築」でMCP(Model Context Protocol)を紹介した。MCPとは、大規模言語モデル(LLM)から外部ツールを呼び出すためのインタフェース仕様である。先の記事では、お天気サーバをMCPサーバに仕立てた簡単な例を紹介した。そこでは、LLM(Claude Desktop)に投げられた質問「今日の大阪の天気を教えて」に答えるため、LLMはMCPサーバを呼び出し、その返答を受け取り、回答を作成しユーザに提示していた。言い換えると、LLMは与えられたタスクを外部ツールに丸投げし、その返答を受け取り回答を作成しただけであった。今回は、MCPから返されたレスポンスの正当性をLLMに吟味させる実験を行う。
今回取り上げたタスクは物体検出である。これをMCPサーバとして実装した。このサーバは、物体の位置と信頼度を返す。ユーザから写真を与えられたLLM(Claude Desktop)は、物体検出のためMCPサーバを呼び出し、物体の位置と信頼度を受け取る。一方で、LLM自体には画像を説明する機能がある。この説明を参照することで、MCPサーバから返された信頼度を補正することができることが分かった。また、検出された物体についても具体的な説明が可能となる。例えば、「犬」が検出された場合、その犬種・毛並み・色などの情報が追加される。さらに、各物体の位置関係についても「画面奥」や「手前」のような修飾が付く。MCPとLLMを連携させることでお互いを補完することができ、質問に対する回答の質を高めることができることが分かった。
入力プロンプトと処理の流れ
LLMとして今回もClaude Desktopを使用する(Claude Desktopは単独では物体検出をサポートしていない)。また、今回実装した物体検出のためのMCPサーバ(以降、物体検出サーバと呼ぶことにする)は、入力としてローカルにある画像ファイルへのパスを受け取り、物体を囲う矩形の位置座標と信頼度を返す。今回使用する入力プロンプトは以下の通りである(Markdown形式で記載した)。

図1
プロンプト内の初期信頼度は物体検出サーバが返した信頼度、補正後信頼度はLLMにより補正された信頼度を表す。今回の処理の流れは以下のようになる。
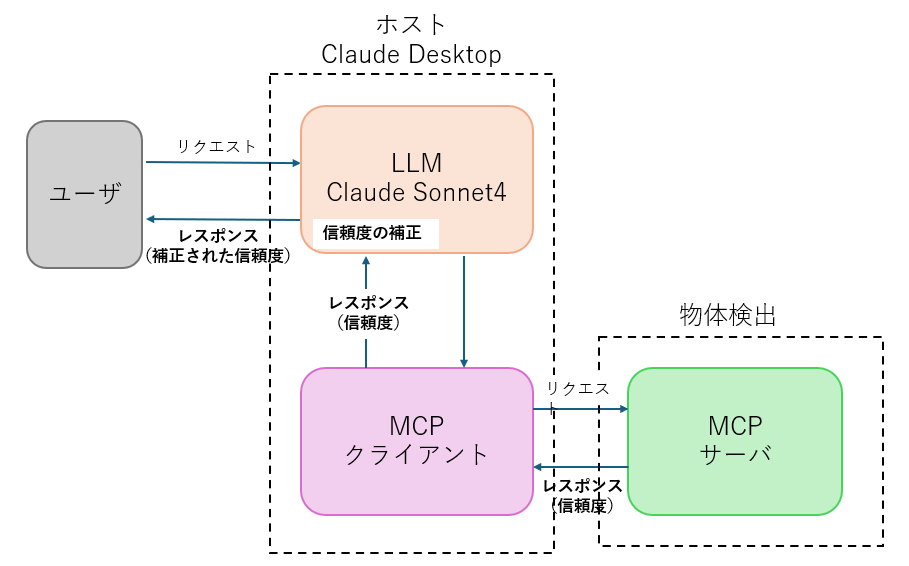
図2
ユーザから受けた質問(入力プロンプトと画像)は、LLMを介して物体検出サーバに渡される。物体検出サーバから信頼度を受け取ったLLMは、自身の画像説明を参照し、必要であれば信頼度を補正し、ユーザに提示する。今回使用した物体検出モジュールは「Yolov8n」である(詳細はこちら)。
実験1
下の左が入力画像(「著作者:freepik」から取得)、右が物体検出サーバが返す画像である(ラベルと信頼度が見にくいので白字で追記した)。

このときの出力は以下の通りである。

猫の信頼度がLLMにより上方に修正されていることが分かる(緑線部分)。また、初期の信頼度が低かった理由が予想され、信頼度が補正された理由が記載されている(赤線部分)。
実験2
下の左が入力画像(「著作者:wirestock/出典:Freepik」から取得)、右が物体検出サーバが返す画像である(ラベルと信頼度が見にくいので白字で追記した)。

このときの出力は以下の通りである。

信頼度が0.46と0.39の鳥は誤検出であるとLLMに判断され、信頼度もゼロに修正されている。この判断は正しい。一方で、残すべき鳥の信頼度は高い値に修正された。
まとめ
今回は、MCPとLLMとを連携させることでユーザへの質の高い回答を作成できることを示した。今回は物体検出をMCPサーバの提供する機能としたが、他の事例も考えられるであろう。
LLM自体の性能が高くなり、物体検出もできるようになると、今回の事例は意味を持たなくなる。生成AIを利用したツール開発の難しさがここにあると思う。