

はじめに
今回は、Googleが公開した「LangExtract」を紹介する。文章の中から、ユーザが必要とする情報だけを抽出するPythonライブラリである。
LangExtractとは
LangExtractとは、LLMを用いて、与えられた文章からユーザがあらかじめ指定した情報を抽出するPythonライブラリである。以前の記事「LLMの出力の構造化データへの変換」で紹介したStructured Outputと呼ばれる手続きと目的は同じである。Structured Outputでは、抽出したい単語がどれであるかはLLMに判断させていた。今回紹介する手法は、ユーザーが定義した少数の例(few-shot examples)に基づき取り出す単語をLLMが判断するため、精度の高い抽出を期待できる。また、Googleが公開したライブラリであるが、バックエンドのLLMとしてOpenAIのモデルも使うことができる。今回は、GPT4oを用いた実験を紹介する(今回のソースコード)。
サンプルコード1
最初に、どのような文章からどのような情報を取り出すのかが分かる具体例を与える。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
def define_extraction_task_02_japanese() -> tuple[str, list[lx.data.ExampleData]]: # Define extraction prompt prompt_description = "テキストから、薬剤名、投薬量、投与経路、投与頻度、投与期間を抽出せよ。" # Define example data with entities in order of appearance examples = [ lx.data.ExampleData( text="患者は250 mgのIVセファゾリンを1日3回、1週間投与された。", extractions=[ lx.data.Extraction(extraction_class="投薬量", extraction_text="250 mg"), lx.data.Extraction(extraction_class="投与経路", extraction_text="IV"), # IV = 静脈内 lx.data.Extraction(extraction_class="薬剤名", extraction_text="セファゾリン"), lx.data.Extraction(extraction_class="投与頻度", extraction_text="1日3回"), lx.data.Extraction(extraction_class="投与期間", extraction_text="1週間"), ], ) ] return prompt_description, examples |
3行目は入力プロンプト、8行目は例文、10行目から14行目までがユーザが望む回答である。この例文と回答をベースにLLMは情報抽出を行う。次に、実際に回答してほしい文章を与える。
|
1 2 3 4 5 6 |
def make_sample_02_japanese(): prompt, examples = define_extraction_task_02_japanese() # The input text to be processed # input_text = "患者はセルニルトン錠を、痛みを感じるときに一回2錠、飲むよう言われた。" input_text = "医師からは、カロナール錠を発熱したときに1回1錠、服用するよう指示された。" return prompt, examples, input_text |
4行目、5行目が情報を抽出したい文章である。以下のコードで実行する。
|
1 2 3 4 5 6 7 8 9 10 11 |
# Run the extraction result = lx.extract( text_or_documents=input_text, prompt_description=prompt, examples=examples, language_model_type=OpenAILanguageModel, model_id="gpt-4o", # api_key=os.environ.get("OPENAI_API_KEY"), fence_output=True, use_schema_constraints=False, ) |
3行目に対象とする文章を、4行目にプロンプトを、5行目に例文とその回答を与えている。7行目に今回利用するモデル名が記載されている。結果は以下の通り(JSON形式)である。対象とした文章内の該当する文字列を赤字で示した。

2つの文章から欲しい情報を正確に取り出せていることが分かる。
サンプルコード2
別の抽出を考える。最初に、具体例を与える。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
def define_extraction_task_03_japanese() -> tuple[str, list[lx.data.ExampleData]]: # Define extraction prompt prompt_description = "テキストから、対象者、日時、場所、イベント、行動を抽出せよ。" # Define example data with entities in order of appearance examples = [ lx.data.ExampleData( text="佐藤さんは、来週火曜日の10時から本社会議室で行われるプロジェクト進捗会議に出席するよう依頼された。", extractions=[ lx.data.Extraction(extraction_class="対象者", extraction_text="佐藤さん"), lx.data.Extraction(extraction_class="日時", extraction_text="来週火曜日の10時"), lx.data.Extraction(extraction_class="場所", extraction_text="本社会議室"), lx.data.Extraction(extraction_class="イベント", extraction_text="プロジェクト進捗会議"), lx.data.Extraction(extraction_class="行動", extraction_text="出席するよう依頼された"), ], ) ] return prompt_description, examples |
3行目は入力プロンプト、8行目は例文、10行目から14行目までがユーザが望む回答である。2つの対象文から情報を抜き出した結果を以下に示す。
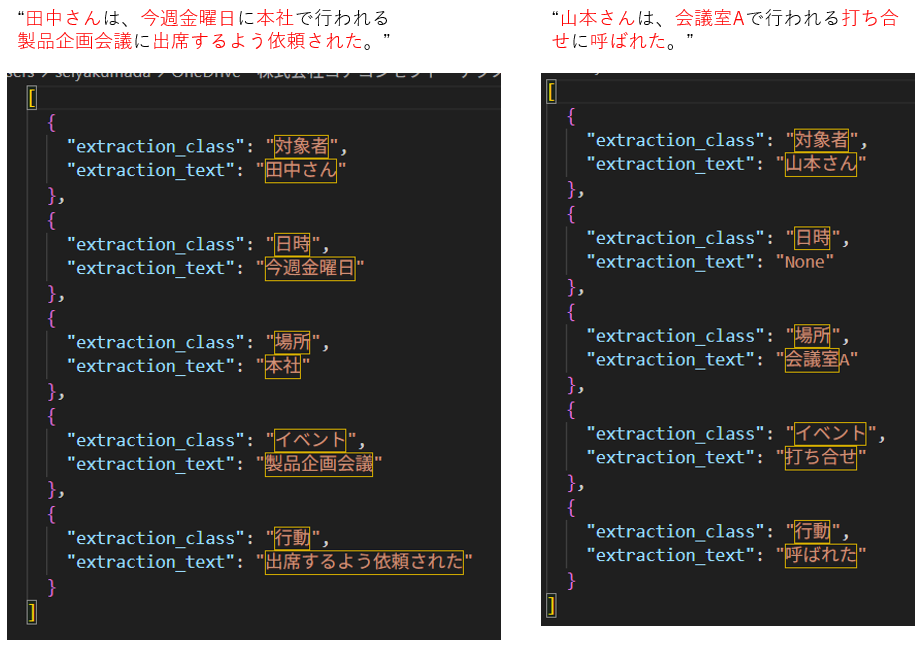
期待する回答を得ていることが分かる。該当する文字列がない場合は、Noneが入る。
まとめ
今回は、与えられた文章から欲しい情報を抽出するライブラリ「LangExtract」を紹介した。この手法は、最初にユーザがタスクの例を提示するため、Structured Outputと呼ばれる手法より正確に単語等を抽出することができる。今回は短文のみを対象としたが、長文対応力も備わっており、大規模文書でも正確性と再現性を確保できると謳われている。